Welcome to the 10 Days SQL Series
This 10‑day SQL series is a structured interview‑prep and upskilling plan that starts from core SQL concepts and gradually moves to advanced, real‑world topics.
You begin with foundational queries and the most common interview questions, then master JSON handling, date/time logic, optimization, and system‑design aspects of SQL.
Here is Day 1 – Top 10 Moderate SQL Interview Questions
The middle days cover transactions, concurrency, theory, and tougher interview problems, followed by advanced aggregations, joins, and robust error handling using stored procedures and CTEs.
The final days focus on complex data scenarios and data modeling, ending with a high‑yield set of frequently asked SQL query questions to solidify your preparation for technical interviews.
Day 1 – Top 10 Moderate SQL Interview Questions
Complete SQL Series Timeline
The aim of this series is to make sure you are able to learn and understand at least 100 of the most asked concepts in SQL interviews.
Bookmark this page, and make sure to be consistent in it. Also, get a notebook and make notes of each question/concept put in here
Day 1 – Basic SQL Questions + Most Asked SQL Interview Questions
Day 2 – JSON, Date and Time SQL Interview Questions
Day 3 – SQL Query Optimization and Data Modeling Interview Questions
Day 4 – Transactions and Concurrency
Day 5 – SQL Hard Interview Questions
Day 6 – Advanced SQL Aggregation + Advanced Joins
Day 7 – Error Handling & Debugging + Stored Procedures & CTE
Day 8 – Complex Data Handling
Day 9 – Data Modeling
Day 10 – SQL Most Asked Query Interview Questions
If you have an interview in near future, you can consider getting 220+ SQL Interview questions in the same split as above in our Best Seller e-book
“Ace ANY SQL Interview“

SQL Interview Questions with Solution
1. Find the Nth Highest Salary (Without LIMIT)
SELECT salary FROM
(SELECT salary, DENSE_RANK() OVER (ORDER BY salary DESC) AS rnk
FROM employees ) t
WHERE rnk = 3;Why Interviewers Ask This: Tests your understanding of window functions vs traditional approaches.
2. Calculate a running total of sales by date
SELECT
order_date,
SUM(sales) OVER (ORDER BY order_date) AS running_total
FROM orders;3. Identify Consecutive Records (Streak Problem)
SELECT user_id
FROM (
SELECT
user_id,
login_date,
login_date - ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) AS grp
FROM logins ) t
GROUP BY user_id, grp
HAVING COUNT(*) >= 3;4. Find missing dates from a continuous date range.
WITH date_series AS
(
SELECT generate_series('2024-01-01'::date, '2024-01-10'::date, interval '1 day') AS dt
)
SELECT dt
FROM date_series
LEFT JOIN orders o ON dt = o.order_date
WHERE o.order_date IS NULL;5. Find the top 3 highest-selling products in each category.
SELECT * FROM
( SELECT
category,
product,
SUM(sales) AS total_sales,
RANK() OVER (PARTITION BY category ORDER BY SUM(sales) DESC) AS rnk
FROM sales
GROUP BY category, product ) t
WHERE rnk <= 3;6. Classify customers based on total spend
SELECT
customer_id,
SUM(amount) AS total_spend,
CASE
WHEN SUM(amount) > 10000 THEN 'High Value'
WHEN SUM(amount) BETWEEN 5000 AND 10000 THEN 'Medium'
ELSE 'Low' END AS segment
FROM transactions
GROUP BY customer_id;7. Find employee-manager relationships.
SELECT
e.name AS employee,
m.name AS manager
FROM employees e
LEFT JOIN employees m ON e.manager_id = m.employee_id;A self join is when a table is joined with itself. It’s commonly used for hierarchical relationships, like:
Employee → Manager
Category → Parent Category
employees e → acts as employee table
employees m → acts as manager table
manager_id links to another row in the same table
Create a raw table on notebook and try to solve this question again
8. How would you optimise a slow performing query?
- Add indexes on frequently filtered columns
CREATE INDEX idx_salary ON employees(salary); - Avoid SELECT *
— Bad SELECT * FROM employees;
— Good SELECT name, salary FROM employees; - Use EXPLAIN PLAN
EXPLAIN SELECT * FROM employees WHERE salary > 50000; - Reduce joins where possible
Only join required tables
Avoid unnecessary columns - Use partitioning for large tables
Example : CREATE INDEX idx_employee_salary ON employees(salary);
9. Difference between CTE and subquery?
Both are used to break down complex queries, but they differ in readability, reuse, and execution.

WITH dept_avg
AS ( SELECT
department,
AVG(salary) AS avg_sal
FROM employees
GROUP BY department )
SELECT * FROM
employees e JOIN dept_avg d ON e.department = d.department
WHERE e.salary > d.avg_sal;Use CTE when:
Complex logic
Multiple steps
Recursive queries
Use Subquery when:
Simple filtering
One-time use
10. Difference between window functions and GROUP BY?
GROUP BY → reduces rows
Window functions → retain rows + add insights
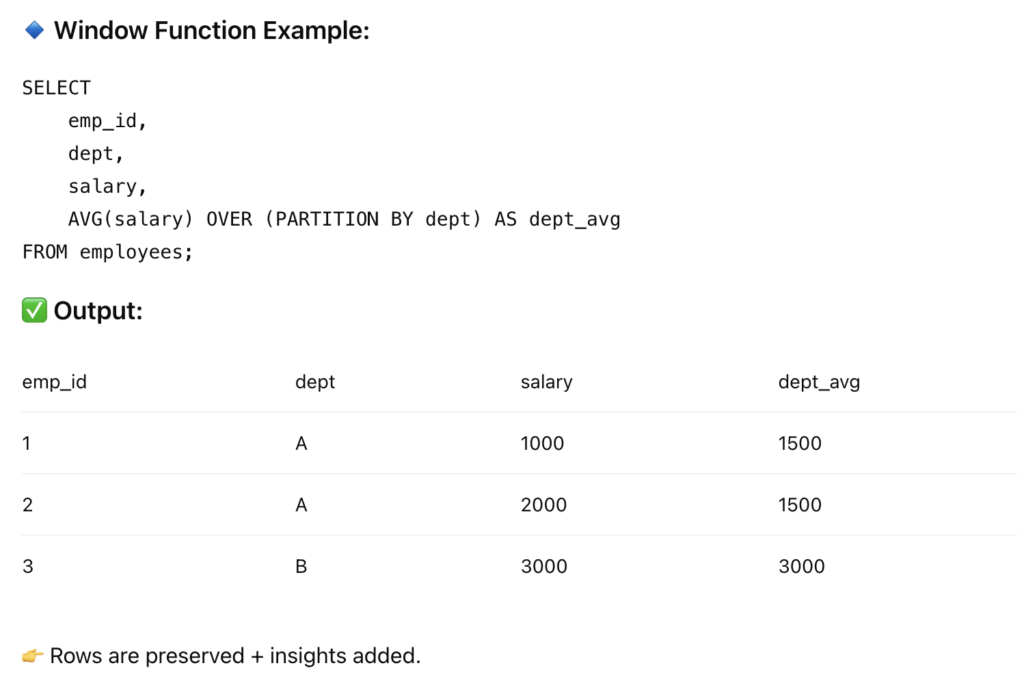

SELECT
employee_id,
department,
salary,
AVG(salary) OVER (PARTITION BY department) AS dept_avg
FROM employees;The Data Monk Best Seller Books and Services
1. Become a Full Stack Analytics Professional in 2026 – 2200 Interview Questions covering 23 topics
2. Book mock interviews/Career Guidance Session on Top Mate to practice
And below is our master class
1 Month Complete 1:1 Mentorship along with 3 e-books, 4 mock interviews, 4 career guidance sessions, and a complete resume review
You can also go through our The Data Monk’s Youtube Channel with 160+ videos across all the top interview topics
