Swiggy Business Analyst Interview Questions
Target job roles – Business Analyst, Data Analyst, Data Scientist, Business Intelligence Engineer, Product Analyst, Machine Learning Engineer, Data Engineer
Target Companies – FAANG and only product-based companies
CTC offered –
12 to 20 LPA for Level 1 (0 to 4 YOE)
20 to 35 LPA for Level 2 (Senior level – 4 to 7 YOE )
35 to 50 LPA for Level 3 (Team Lead or Manager – 7 to 9 YOE)
50 to 80 LPA for Level 4 (Manager or Senior Manager – 9 to 12 YOE)
Tools and Technologies required
SQL – 9/10
Python – 7/10
Visualization tool (Power BI or Tableau) – Good to have
Machine Learning Algorithm – Expert in at least a couple of algorithms (if going for Data Science role)
Swiggy Business Analyst Interview Questions
Why The Data Monk?
We are a group of 30+ people with ~8 years of Analytics experience in product-based companies. We take interviews on a daily basis for our organization and we very well know what is asked in the interviews.
Other skill enhancer website charge 2lakh+ GST for courses ranging from 10 to 15 months.
We only focus on making you a clear interview with ease. We have released our Become a Full Stack Analytics Professional for anyone in 2nd year of graduation to 8-10 YOE. This book contains 23 topics and each topic is divided into 50/100/200/250 questions and answers. Pick the book and read it thrice, learn it, and appear in the interview.
We also have a complete Analytics interview package
– 2200 questions ebook (Rs.1999) + 23 ebook bundle for Data Science and Analyst role (Rs.1999)
– 4 one-hour mock interviews, every Saturday (top mate – Rs.1000 per interview)
– 4 career guidance sessions, 30 mins each on every Sunday (top mate – Rs.500 per session)
– Resume review and improvement (Top mate – Rs.500 per review)
Total cost – Rs.10500
Discounted price – Rs. 9000
How to avail of this offer?
Send a mail to nitinkamal132@gmail.com
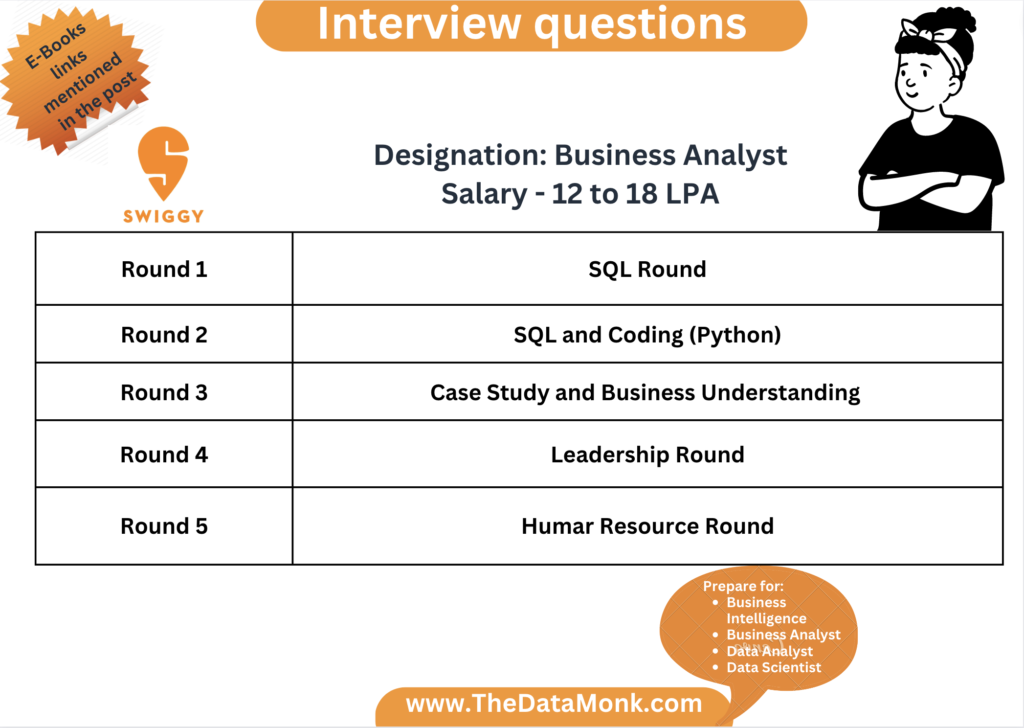
Swiggy Business Analyst Interview Questions
Company – Swiggy
Designation – Business Analyst
Year of Experience required – 0 to 3 years
Technical expertise – SQL, Python, Case Study
Salary offered – 12 to 18 LPA (no Stocks, 10% variable) – 50% hike
Number of Rounds – 5
Swiggy SQL Interview Questions
Following are the type of questions asked in Swiggy for the post of Business Analyst. The post was for Business Analyst in the FP&A vertical and thus required a good grasp on technical stuff. Practice the below questions
What is a primary key in SQL, and why is it important?
A primary key is a unique identifier for a record in a table. It is a column or a set of columns that uniquely identify each record in the table. Primary keys are important because they ensure data integrity and facilitate efficient searching, sorting, and indexing of data. They also help to prevent duplicate records and ensure that each record in the table has a unique identifier.
What is normalization, and why is it important in database design?
Normalization is the process of organizing data in a database in a way that reduces redundancy and dependency. It involves dividing large tables into smaller tables and defining relationships between them. Normalization helps to ensure data consistency and accuracy, and it also improves database performance by reducing data duplication and improving data retrieval efficiency.
What is a join in SQL, and how does it work?
A join in SQL is used to combine data from two or more tables based on a common field or column. It allows you to retrieve data from multiple tables in a single query. There are different types of joins in SQL, including inner join, left join, right join, and full outer join. Each type of join returns a different set of results based on the relationship between the tables being joined.
What is the difference between a left join and an inner join?
An inner join in SQL returns only the rows that have matching values in both tables being joined. A left join, on the other hand, returns all the rows from the left table and matching rows from the right table. If there is no match in the right table, the result will still include the row from the left table, but the columns from the right table will be NULL.
What is an index in SQL, and why would you use one?
An index in SQL is a data structure that allows for faster retrieval of data from a database. It is used to improve the performance of SELECT, JOIN, and WHERE clauses by creating a sorted copy of the data in the table. Indexes help to reduce the amount of time it takes to search for data in a table, and they also help to minimize disk I/O by allowing the database engine to locate data more efficiently.
What is a subquery in SQL, and how is it different from a join?
A subquery in SQL is a query within another query. It is used to retrieve data from one or more tables based on a condition that is defined in the outer query. A subquery can be used in place of a table in a join, but it is different from a join in that it is executed separately from the outer query. A join combines data from two or more tables into a single result set, whereas a subquery returns a result set that is used by the outer query.
What is a stored procedure in SQL, and why would you use one?
A stored procedure in SQL is a precompiled set of SQL statements that are stored in the database and can be executed repeatedly. It is used to encapsulate complex business logic and repetitive tasks that can be reused across multiple applications. Stored procedures help to improve database performance, simplify maintenance, and ensure data consistency by reducing the amount of network traffic and SQL code that needs to be sent to the server.
What is a trigger in SQL, and when would you use one?
A trigger in SQL is a set of SQL statements that are automatically executed in response to certain events, such as INSERT, UPDATE, or DELETE operations on a table. Triggers are used to enforce business rules, maintain data consistency, and ensure data integrity by automatically performing certain actions based on changes to the data in a table.
Query Questions
Explain with an example and use case of Self Join
SQL query optimisation techniques
We have put all the 250 most asked questions in our SQL Interview Questions e-book. Do check it out
Swiggy Case Study Interview Questions
What are the factors to consider if you work in the sales department of Samsung and you want to start a store in one of the most crowded malls of Bangalore?
Think through all the points like
-Foot fall
-Customers
-Break-even point of profit
-Exit points if things fail
Approach:
Foot fall
1. Variations during weekdays and weekends (any particular hours of max crowding?)
2. Uptick during mall promotional activities (a general campaign during a holiday which invites people to the mall)
3. Variations as per the mall floor (does 1st floor have more relevant neighboring shops than the ground floor and hence attracts more potential customers?)
4. Maximum capacity during any day and average footfall per store, per type.
Customers
1. Are they coming from different parts of Bangalore or just neighboring ones? Is the mall accessible?
2. The profile of a customer – do college kids visit more or a mix of families and young working professionals? Any idea of the breakup?
3. Is the locality posh and upscale?
Supply and demand issue (connect with warehouse)
1. How far is the warehouse from the store? Can it ensure that there is no stock-out ever?
2. What is the capacity of that warehouse? Can it cater to the market demand and replenish stock in a periodic manner?
3. Demand generation activities – Do mall visitors respond to promo activities done inside (or outside) the mall?
Break-even point of profit
1. Cost headers – Rent, salaries, inventory holding, promo activities (in and beyond the mall, including discounts), supply chain (trucking).
2. Revenue headers – sales made as per SKU (Did low-priced handsets sell more or high-priced ones sold less but contributed more to the overall revenue?)
Exit points if things fail
1. Relocation within the mall or an area near it?
2. Identify the main reason of failure – was it due to competitors’ presence?
Swiggy Top 20 KPIs for Dashboard
Gross merchandise value (GMV) – The total value of all orders placed on the platform
Number of orders processed – The total number of orders fulfilled by the platform
Average order value (AOV) – The average value of each order
Customer acquisition cost (CAC) – The cost of acquiring new customers through marketing and advertising efforts
Customer retention rate – The percentage of customers who return to use the platform again
Repeat orders – The percentage of orders that come from returning customers
Delivery time – The time it takes for an order to be delivered to the customer
Delivery success rate – The percentage of orders that are successfully delivered to customers
Delivery cost – The cost of delivering orders to customers
Average delivery distance – The average distance between the restaurant and the customer
Average restaurant rating – The average rating given to restaurants on the platform
Customer satisfaction score (CSAT) – The percentage of customers who rate their experience with the platform positively
Net promoter score (NPS) – A measure of customer loyalty and satisfaction
Average preparation time – The average time it takes for restaurants to prepare orders
Restaurant retention rate – The percentage of restaurants that continue to partner with the platform
Commission rate – The percentage of revenue that the platform takes from each order
Order cancellation rate – The percentage of orders that are cancelled by either the customer or the restaurant
Order accuracy rate – The percentage of orders that are fulfilled without errors
Average delivery ratings – The average rating given to delivery partners by customers
Sales growth rate – The percentage increase in sales over a given period of time.
We have 100 case studies and guesstimate completely solved that are repeatedly asked in Analytics Interview. Do check it out.
Swiggy Technical Interview Questions
What are the main components of the Hadoop ecosystem, and what are their roles?
The main components of the Hadoop ecosystem include:
Hadoop Distributed File System (HDFS) – a distributed file system that stores data across multiple nodes in a cluster.
Yet Another Resource Negotiator (YARN) – a framework that manages resources and schedules tasks across the cluster.
MapReduce – a programming model for processing large data sets in parallel across multiple nodes in a cluster.
Hadoop Common – a set of utilities and libraries that are used by other Hadoop modules.
What is MapReduce, and how does it work?
MapReduce is a programming model for processing large data sets in parallel across multiple nodes in a cluster. It consists of two phases:
Map phase – where the input data is divided into small chunks and processed in parallel across multiple nodes.
Reduce phase – where the intermediate results are combined to produce the final output.
What is the difference between Hadoop and Spark?
Hadoop and Spark are both Big Data processing frameworks, but they have some key differences. Hadoop is a batch processing framework that relies on MapReduce for processing large data sets. Spark, on the other hand, is an in-memory processing framework that can handle both batch and real-time processing. Spark is also generally faster than Hadoop due to its ability to keep data in memory, whereas Hadoop needs to write intermediate results to disk.
What is Spark, and what are its main components?
Apache Spark is an open-source, in-memory distributed computing framework that can handle both batch and real-time processing. Its main components include:
Spark Core – the basic processing engine for distributed data processing.
Spark SQL – a module for processing structured data using SQL-like queries.
Spark Streaming – a module for processing real-time data streams.
Spark MLlib – a module for machine learning tasks.
Spark GraphX – a module for graph processing.
What is the difference between batch processing and real-time processing?
Batch processing is a method of processing large volumes of data in a scheduled, periodic manner. The data is collected, stored, and processed at specific intervals. Real-time processing, on the other hand, processes data as it is generated, in real-time. This allows for immediate processing and response to events as they occur, without waiting for the next scheduled batch processing run.
What is Kafka, and what is it used for?
Apache Kafka is an open-source distributed streaming platform that is used for building real-time streaming data pipelines and applications. It is designed to handle high volumes of data and enables applications to publish, subscribe to, store, and process streams of data in real-time.
What is NoSQL, and when would you use it?
NoSQL, or “not only SQL,” is a database management system that is used for handling large volumes of unstructured or semi-structured data. Unlike traditional SQL databases, NoSQL databases are schema-less and can handle different data formats and types. NoSQL databases are used in Big Data applications where data is constantly changing and traditional relational databases are not suitable. NoSQL databases are also often used in real-time applications, such as web applications, where high scalability and availability are required.
Swiggy Behavioral and Hiring Manager Interview Questions
- Tell me a time or situation when you trained someone who was not up to the mark and then made him excel in some work?
2. How will you handle a team when the team lead is not there
3. Why are you switching the company so frequently?
4. When was the hardest time of your professional career
All the questions asked above and in 50+ Analytics companies are covered head to toe in our 2200 Interview Questions to become full stack Analytics Professional book. Do check out
The Data Monk Product and Services
- Youtube Channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel - Website – ~2000 completed solved Interview questions in SQL, Python, ML, and Case Study
Link – The Data Monk website - E-book shop – We have 70+ e-books available on our website and 3 bundles covering 2000+ solved interview questions
Link – The Data E-shop Page - Mock Interviews
Book a slot on Top Mate - Career Guidance/Mentorship
Book a slot on Top Mate - Resume-making and review
Book a slot on Top Mate
The Data Monk e-book Bundle
1.For Fresher to 7 Years of Experience
2000+ interview questions on 12 ML Algorithm,AWS, PCA, Data Preprocessing, Python, Numpy, Pandas, and 100s of case studies
2. For Fresher to 1-3 Years of Experience
Crack any analytics or data science interview with our 1400+ interview questions which focus on multiple domains i.e. SQL, R, Python, Machine Learning, Statistics, and Visualization
3.For 2-5 Years of Experience
1200+ Interview Questions on all the important Machine Learning algorithms (including complete Python code) Ada Boost, CNN, ANN, Forecasting (ARIMA, SARIMA, ARIMAX), Clustering, LSTM, SVM, Linear Regression, Logistic Regression, Sentiment Analysis, NLP, K-M