What do you mean when I say “The model has high accuracy in Training dataset but low in testing dataset”
Data Science model interview question
Answer by Swapnil
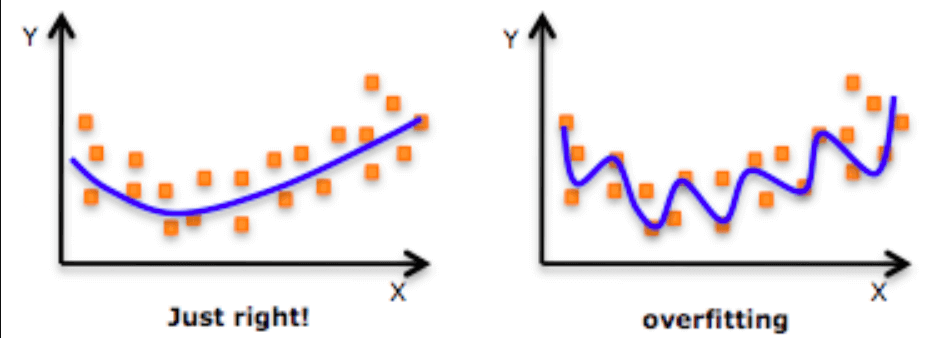
It means the model is getting trained to the noise in the data and trying to fit exactly to the training data rather than generalizing it well over many different data sets. So, the model is suffering from high variance in the test set and the solution is to introduce a little bit of bias in the model so that it reduces the variance in the test set. This is also called as overfitting in technical terms.
Answer by Shubham Bhatt
“The model has high accuracy in Training dataset but low in testing dataset” means overfitting.
When a model gets trained with so much of data, it starts learning from the noise and inaccurate data entries in our data set. Then the model does not categorize the data correctly, because of too many details and noise. The causes of overfitting are the non-parametric and non-linear methods because these types of machine learning algorithms have more freedom in building the model based on the dataset and therefore they can really build unrealistic models. A solution to avoid overfitting is using a linear algorithm if we have linear data or using the parameters like the maximal depth if we are using decision trees.
It suggests “High variance and low bias”.
Techniques to reduce overfitting :
1. Increase training data.
2. Reduce model complexity.
3. Early stopping during the training phase (have an eye over the loss over the training period as soon as loss begins to increase stop training).
4. Ridge Regularization and Lasso Regularization
5. Use dropout for neural networks to tackle overfitting.
Answer by SMK – The Data Monk user
Data Science model interview question
1) This is a case of overfitting a model. It happens when a model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data
2) Overfitting is more likely with nonparametric and nonlinear models that have more flexibility when learning a target function. For example, decision trees are a nonparametric machine learning algorithm that is very flexible and is subject to overfitting training data. We can prune a tree after it has learned in order to remove some of the detail it has picked up
3) Techniques to limit overfitting:
a) Use a resampling technique to estimate model accuracy
– k-fold cross-validation: We partition the data into k subsets, called folds. Then, we iteratively train the algorithm on k-1 folds while using the remaining fold as the test set (called the “holdout fold”).
b) Hold back a validation dataset – A validation dataset is simply a subset of your training data that you hold back from your algorithms until the very end of your project. After you have tuned your algorithms on your training data, you can evaluate the learned models on the validation dataset to get a final objective idea of how the models might perform on unseen data
c) Remove irrelevant input features (Feature selection)
d) Early Stopping: Up until a certain number of iterations, new iterations improve the model. After that point, however, the model’s ability to generalize can weaken as it begins to overfit the training data. Early stopping refers to stopping the training process before the learner passes that point. Deep Learning uses this technique.
Answer by Harshit Goyal
Data Science model interview question
The model’s high accuracy in the training dataset but low in the testing dataset is due to overfitting.
Overfitting is a modeling error that occurs when a function is too closely fit to a limited set of data points.
In reality, the data often studied has some degree of error or random noise within it. Thus, attempting to make the model conform too closely to slightly inaccurate data can infect the model with substantial errors and reduce its predictive power.
Therefore, the model fails to fit additional data or predict future observations reliably.
The Data Monk Interview Books – Don’t Miss
Now we are also available on our website where you can directly download the PDF of the topic you are interested in. At Amazon, each book costs ~299, on our website we have put it at a 60-80% discount. There are ~4000 solved interview questions prepared for you.
10 e-book bundle with 1400 interview questions spread across SQL, Python, Statistics, Case Studies, and Machine Learning Algorithms – Ideal for 0-3 years experienced candidates
23 E-book with ~2000 interview questions spread across AWS, SQL, Python, 10+ ML algorithms, MS Excel, and Case Studies – Complete Package for someone between 0 to 8 years of experience (The above 10 e-book bundle has a completely different set of e-books)
12 E-books for 12 Machine Learning algorithms with 1000+ interview questions – For those candidates who want to include any Machine Learning Algorithm in their resume and to learn/revise the important concepts. These 12 e-books are a part of the 23 e-book package
Individual 50+ e-books on separate topics
Important Resources to crack interviews (Mostly Free)
There are a few things which might be very useful for your preparation
The Data Monk Youtube channel – Here you will get only those videos that are asked in interviews for Data Analysts, Data Scientists, Machine Learning Engineers, Business Intelligence Engineers, Analytics managers, etc.
Go through the watchlist which makes you uncomfortable:-
All the list of 200 videos
Complete Python Playlist for Data Science
Company-wise Data Science Interview Questions – Must Watch
All important Machine Learning Algorithm with code in Python
Complete Python Numpy Playlist
Complete Python Pandas Playlist
SQL Complete Playlist
Case Study and Guesstimates Complete Playlist
Complete Playlist of Statistics