We know that each domain requires a different type of preparation, so we have divided our books in the same way:
Our best seller:
✅Become a Full Stack Analytics Professional with The Data Monk’s master e-book with 2200+ interview questions covering 23 topics – 2200 Most Asked Interview Questions
Machine Learning e-book
✅Data Scientist and Machine Learning Engineer ->23 e-books covering all the ML Algorithms Interview Questions
Domain wise interview e-books
✅Data Analyst and Product Analyst Interview Preparation ->1100+ Most Asked Interview Questions
✅Business Analyst Interview Preparation ->1250+ Most Asked Interview Questions
The Data Monk – 30 Days Mentorship program
We are a group of 30+ people with ~8 years of Analytics experience in product-based companies. We take interviews on a daily basis for our organization and we very well know what is asked in the interviews.
Other skill enhancer websites charge 2lakh+ GST for courses ranging from 10 to 15 months.
We only focus on making you a clear interview with ease. We have released our Become a Full Stack Analytics Professional for anyone in 2nd year of graduation to 8-10 YOE. This book contains 23 topics and each topic is divided into 50/100/200/250 questions and answers. Pick the book and read it thrice, learn it, and appear in the interview.
We also have a complete Analytics interview package
– 2200 questions ebook (Rs.1999) + 23 ebook bundle for Data Science and Analyst role (Rs.1999)
– 4 one-hour mock interviews, every Saturday (top mate – Rs.1000 per interview)
– 4 career guidance sessions, 30 mins each on every Sunday (top mate – Rs.500 per session)
– Resume review and improvement (Top mate – Rs.500 per review)
YouTube channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel
MasterCard Data Science Interview Questions
Company: Mastercard
Position: Data Scientist
Location: Gurugram
Salary: 12LPA – 30LPA
Mastercard Incorporated, headquartered in Purchase, New York, is a global leader in financial services. Known for its innovative payment solutions and commitment to financial inclusion, Mastercard operates in over 210 countries and territories. If you’re preparing for a Data Science role at Mastercard, here’s a detailed breakdown of their interview process and the types of questions you can expect.
Mastercard Data Science Interview Questions.

Interview Process
The Mastercard Data Science interview process typically consists of 5 rounds, each designed to evaluate different aspects of your technical and analytical skills:
Round 1 – Telephonic Screening
Focus: Basic understanding of Data Science concepts, SQL, and Python/R.
Format: You’ll be asked to explain your projects and solve a few coding or SQL problems.
Round 2 – Walk-in/Face-to-Face Technical Round
Focus: Advanced SQL, coding, and problem-solving.
Format: You’ll solve problems on a whiteboard or shared document.
Round 3 – Project Analysis
Focus: Deep dive into your past projects.
Format: You’ll be asked to explain your approach, tools used, and the impact of your work.
Round 4 – Case Studies
Focus: Business problem-solving and data-driven decision-making.
Format: You’ll be given a real-world scenario and asked to propose solutions.
Round 5 – Hiring Manager Round
Focus: Cultural fit, communication skills, and long-term career goals.
Format: Behavioral questions and high-level discussions about your experience.
Difficulty of Questions
SQL – 9/10
1) How can you find employees who have never taken leave from the leaves table?
SELECT e.name
FROM employees e
LEFT JOIN leaves l ON e.id = l.employee_id
WHERE l.employee_id IS NULL;2) How can you find the most recently hired employee?
SELECT name, joining_date
FROM employees
ORDER BY joining_date DESC
LIMIT 1;3) How can you count the number of orders placed by each customer from an orders table?
SELECT customer_id, COUNT(*) AS total_orders
FROM orders
GROUP BY customer_id;4) How can you find customers who have never placed an order?
SELECT c.name
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
WHERE o.customer_id IS NULL;5) How can you find the employee with the second-highest experience based on joining_date?
SELECT name, joining_date
FROM employees
ORDER BY joining_date ASC
LIMIT 1 OFFSET 1;R/Python – 7/10
1) Write a Python function that takes a string as input and returns a list of all email addresses found in the string, using the re module.

2) Write a Python function that takes two date strings in the format “YYYY-MM-DD” as input and returns the number of days between them.
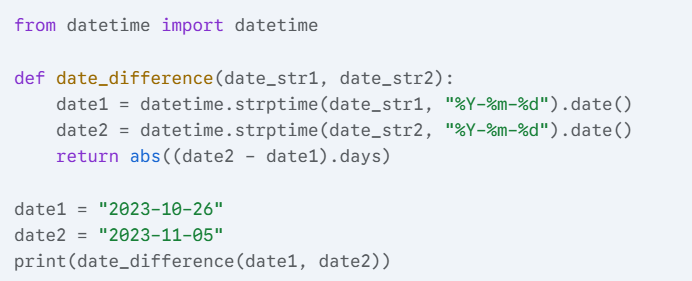
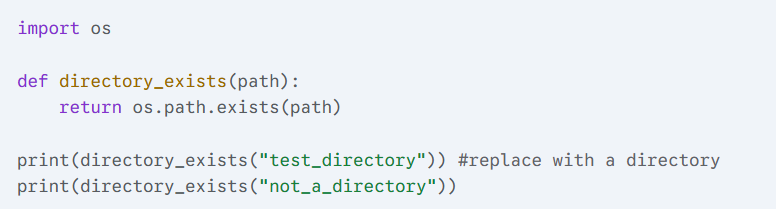
3) Write a Python function that checks if a directory exists.
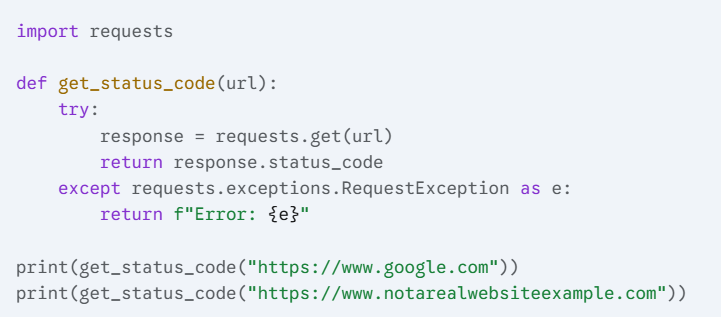
4) Write a Python function that makes a GET request to a given URL and returns the status code of the response.
5) Write a Python function that creates and starts a new thread that prints “Hello from thread!” after a short delay.

Statistics/ML
1) State one situation where the set-based solution is advantageous over the cursor-based solution.
A set-based solution is preferred when handling large data operations efficiently.
Example: Updating salaries for all employees in a company.
- Set-Based Approach: UPDATE Employee SET Salary = Salary * 1.10 (executes in one go).
- Cursor-Based Approach: Fetch each employee row, update salary, and commit changes (slow and inefficient).
Conclusion: Set-based solutions are faster and more scalable than cursors for bulk operations.
2) Design a recommendation engine from end to end from a dataset to deployment in production.
To build a recommendation system:
- Data Collection – Gather user interactions, purchase history, ratings.
- Data Preprocessing – Clean, normalize, and remove inconsistencies.
- Feature Engineering – Create useful features like user preferences, purchase frequency.
- Model Selection – Choose between:
- Collaborative Filtering (User-User, Item-Item)
- Content-Based Filtering (based on product descriptions, user interests)
- Training and Evaluation – Train on historical data, evaluate using Precision, Recall, RMSE.
- Deployment – Use cloud platforms like AWS, Google Cloud, or Flask APIs for real-time recommendations.
- Continuous Monitoring – Track user behavior and update recommendations dynamically.
Example: Netflix recommends shows based on viewing history using collaborative filtering.
3) Explain what metrics we should use to evaluate a binary classification model.
Key metrics for evaluating a binary classification model:
- Accuracy – Measures overall correctness: (TP + TN) / (TP + TN + FP + FN).
- Precision – How many predicted positives are correct: TP / (TP + FP).
- Recall (Sensitivity) – How many actual positives are detected: TP / (TP + FN).
- F1-Score – Harmonic mean of precision and recall: 2 × (Precision × Recall) / (Precision + Recall).
- ROC-AUC Score – Measures model’s ability to distinguish between classes.
Example: In spam detection, high recall is important to catch all spam emails, even if some false positives occur.
4) How can you design a product recommendation system based on taxonomy?
A taxonomy-based recommendation system organizes products into categories and subcategories.
Steps:
- Define Taxonomy – Group products based on attributes (e.g., Electronics → Phones → Smartphones).
- User Profile Matching – Match user preferences to taxonomy-based categories.
- Content-Based Filtering – Recommend similar products within the same taxonomy.
- Hybrid Approach – Combine taxonomy-based filtering with collaborative filtering for better recommendations.
Example: Amazon suggests “Smartphones” when a user buys “Wireless Earbuds” using category-based recommendations.
5) A person using a search engine needs to find something. How do you come up with an algorithm that will predict what the user needs after they type only a few letters?
To predict a user’s search intent based on partial input, we can use Auto-Complete Algorithms:
- N-gram Models – Suggest words based on previous search patterns.
- Trie Data Structure – Efficiently stores and retrieves prefix-based suggestions.
- Machine Learning (ML) Models – Train on past searches to predict relevant queries.
- Personalization – Use a user’s past search history for customized predictions.
- Real-time Updates – Continuously improve suggestions based on trending searches.
Example: Google suggests “Python tutorial” when a user types “Py” based on N-gram frequency analysis.
Case Study
Problem Statement:
Mastercard wants to improve its fraud detection system by identifying fraudulent transactions in real-time while minimizing false positives. Your task as a data scientist is to analyze transaction data, detect suspicious patterns, and develop strategies to enhance fraud prevention.
Dataset Overview:
You have access to a dataset containing past transaction records with fraud labels. The dataset includes the following attributes:
Dataset Overview:
You have access to a dataset containing past transaction records with fraud labels. The dataset includes the following attributes:
- Transaction_ID – Unique identifier for each transaction
- User_ID – Unique identifier for the cardholder
- Transaction_Amount – Amount spent in the transaction
- Merchant_Category – Type of merchant (e.g., grocery, electronics, luxury, travel)
- Transaction_Location – Location where the transaction occurred
- Transaction_Timestamp – Date and time of the transaction
- Device_Type – Device used for the transaction (mobile, desktop, ATM, POS)
- IP_Address – IP address of the transaction source
- Previous_Fraud_Flag – Whether the user has reported fraud before (1 = Yes, 0 = No)
- Transaction_Status – 1 if the transaction is fraudulent, 0 if legitimate
Key Questions to Answer:
1. What are the key indicators of fraudulent transactions?
- Do fraudsters prefer certain transaction locations or merchant categories?
- Are there patterns in transaction amounts that indicate fraud?
- Does the frequency of transactions within a short time frame help detect fraud?
2. How can Mastercard improve fraud detection?
- Should Mastercard use rule-based models or machine learning algorithms for fraud detection?
- Can real-time anomaly detection reduce fraud while maintaining transaction speed?
- How can external factors like device type and IP address enhance fraud detection models?
3. What strategies can Mastercard implement to minimize false positives?
- How can Mastercard balance fraud detection and user experience?
- Should Mastercard use dynamic risk scoring instead of blocking transactions outright?
- How can Mastercard refine fraud prevention using historical user behavior analysis?
Key Insights & Business Recommendations
1. Identifying Key Fraud Patterns
- Unusual Transaction Amounts: Transactions that deviate significantly from a user’s normal spending behavior are often fraudulent.
- Geographical Mismatch: If a card is used in two different countries within a short time frame, it may indicate fraud.
- Device and IP Address Anomalies: Fraudsters often use new devices and VPNs to hide their locations, making these key fraud indicators.
- High-Frequency Transactions: Multiple transactions in a short time span, especially at high-risk merchants (e.g., electronics stores, luxury retailers), can indicate fraud.
2. Enhancing Fraud Detection Models
- Machine Learning-Based Risk Scoring: Implementing an AI-driven fraud detection system that continuously learns from new fraud patterns.
- Real-Time Anomaly Detection: Using unsupervised learning models (e.g., autoencoders, clustering) to detect unusual spending behavior.
- Behavioral Biometrics: Analyzing how users interact with payment platforms (e.g., typing speed, mouse movements) to detect fraudulent behavior.
- Two-Factor Authentication (2FA) Triggers: Requiring extra verification for high-risk transactions based on spending behavior and location.
3. Minimizing False Positives for Better Customer Experience
- Personalized Risk-Based Authentication: Instead of outright rejecting transactions, flagging them for step-up authentication (e.g., OTP verification, biometric confirmation).
- Dynamic Fraud Thresholds: Adjusting fraud detection thresholds based on user history to prevent blocking legitimate transactions.
- Real-Time Customer Alerts: Notifying users of potentially fraudulent transactions and allowing them to verify or dispute them instantly.
Basic, you can practice a lot of case studies and other statistics topics here –
https://thedatamonk.com/data-science-resources/