Big Data Pipeline Infrastructure consists of a lot of components and as an analyst, you are expected to understand the complete infrastructure in order to provide better insights on data lineage, integrity, finding loopholes in the source, and final data.
In this blog, we will discuss the most important part of Big Data Pipeline Infrastructure in brief, why brief? because in every organization the technology stack will be different, so you need to dig deep into those components which are currently being used in your organization.
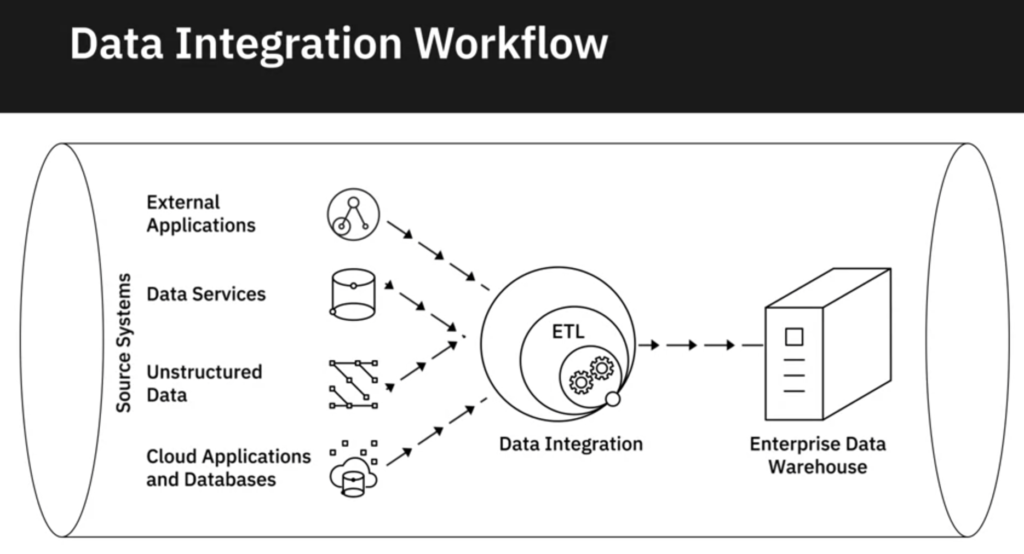
Above is a diagram of the overall picture of a complete infrastructure
Data Source
What is a data source?
Anything and everything which creates data is a source. Suppose you have a small sweet shop, then your register which can be turned into an excel sheet is a source of data. Now, you launched an application and a website, thus your new sources are from these applications. Your sweet shop became popular, so you started getting mentions on Twitter (Woohoo !!) , now you have another source of data that you can pull from an API.
All these are your source of data. In general following are the major sources of data:-
1. APIs
2. Web services
3. Data Stream
4. Clickstream Data
5. Social platform
6. Sensor deives
Types of Data
What are the different types of data?
Take the same example as above, you have now two types of data:-
-Structured – Very simple to understand, all your data which can be put in a table (rows and columns) and which follow all the general principles like primary keys, ACID properties, etc. will fall into structured data
-Semi-structured – These are the sources that are sort of structured and you can write a SQL query to get results from here, but it’s not optimal for writing queries. Example – Suppose you have maintained a register for the phone numbers of your top customers. You created one column for each customer, now JIO launched a dual sim and every customer now has two phone numbers. Next year, iPhone will launch a simple and cheap phone (in your dreams) and everyone will have another phone. Increasing the number of columns each time is not a feasible solution.
Solution – Create a column with JSON filed and put all the phone numbers in it, in fact, put all the customer level information in one column of the table. Explore more about JSON on google.
This is an example of semi-structured data. Another example is XML
-Unstructured – Suppose you want to store videos, images, and other types of multimedia data, these are completely unstructured and has a separate way of storing
Where to store the data?
You have a lot of data, but every data is not of the same nature. There are multiple ways to store these data points:-
– Relational DataBase Management System (RDBMS) – Here you can store your structured data in a proper format with all the conventions like ACID property, in rows and columns, keys, etc.
Examples of RDBMS are IBM DB2, MySQL, Oracle Database, PostgreSQL
-NoSQL – Explore more about NoSQL in this blog
Here data is stored in a key-value pair or in a document type, these are complicated to query as these contain semistructured and unstructured data
Example – Redic, MongoDB, Cassandra, Neo4j
Database vs Data warehouse vs Data Lake
Where to store these databases?
First of all database as discussed above is a collection of data for input, storage, search and retrieval of data
It is of two types – RDBMS and NoSQL
Data warehouse is clubbing some databases into one comprehensive dataset for analytical and Business Intelligence purposes. Example – Oracle Exadata, Amazon Redshift, IBM DB2 Warehouse
Data warehouses mostly store transactional data
Data Mart – Subsection of a data warehouse built specifically for a purpose. In the sweet store example, you can have a data warehouse with all the data, but you can create multiple datamarts each for domains like sales, revenue, clickstream data, etc.
Data Lake – It stores large amounts of structured,semi-structured, and unstructured data in their native format. Data can be loaded without knowing the schema of the data. It is very easy to scale if the volume of data increases.
How to move data from source to your table?
You have your data in the source, now there are mainly two ways to load the data in your table:-
1. ETL – It stands for Extract Transform and Load, here the data is extracted from the source. Suppor after extracting you need to make some changes in the table like splitting name into First and last name or masking the phone number of customer, etc. Then that part is called transforming. Once transformation is done, we load it to a warehouse
2. ELT – It stands for Extract Load and Transform – Extracted data is first loaded in a data repository which could be a data lake or data warehouse. It is helpful in processing large datasets of structured and non-relational database
The data pipeline is a broader term of ETL and ELT, a superset of these two. Data pipeline encompassed complete journey from one system to another.
The Data Monk services
We are well known for our interview books and have 70+ e-book across Amazon and The Data Monk e-shop page . Following are best-seller combo packs and services that we are providing as of now
- YouTube channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel - Website – ~2000 completed solved Interview questions in SQL, Python, ML, and Case Study
Link – The Data Monk website - E-book shop – We have 70+ e-books available on our website and 3 bundles covering 2000+ solved interview questions. Do check it out
Link – The Data E-shop Page - Instagram Page – It covers only Most asked Questions and concepts (100+ posts). We have 100+ most asked interview topics explained in simple terms
Link – The Data Monk Instagram page - Mock Interviews/Career Guidance/Mentorship/Resume Making
Book a slot on Top Mate
The Data Monk e-books
We know that each domain requires a different type of preparation, so we have divided our books in the same way:
1. 2200 Interview Questions to become Full Stack Analytics Professional – 2200 Most Asked Interview Questions
2.Data Scientist and Machine Learning Engineer -> 23 e-books covering all the ML Algorithms Interview Questions
3. 30 Days Analytics Course – Most Asked Interview Questions from 30 crucial topics
You can check out all the other e-books on our e-shop page – Do not miss it
For any information related to courses or e-books, please send an email to nitinkamal132@gmail.com