Swiggy Data Analyst Interview Questions
Name of company – Swiggy
Designation – Data Analyst
Salary – 10 to 12 LPA
Number of rounds – 3
Swiggy Data Analyst Interview Questions

Swiggy Data Analyst Interview Questions
There were in total 4 rounds in LinkedIn for the post of Business Analyst post. The focus was mostly on SQL and case studies.
Swiggy Data Analyst Interview Questions
There were in total 4 rounds
Round 1 – SQL, Python and Case Study
Round 2 – Statistics and Big data
Round 3 – Hiring Manager Round
Below are some questions that were asked in these technical round
SQL Questions
Q. What is the purpose of DDL Language?
Ans:- DDL stands for Data definition language. It is the subset of a database that defines the data structure of the database when the database is created. For example, we can use the DDL commands to add, remove, or modify tables. It consists of the following commands: CREATE, ALTER and DELETE database objects such as schema, tables, indexes, view, sequence, etc.
Example
- CREATE TABLE Students
- (
- Roll_no INT,
- Name VARCHAR(45),
- Branch VARCHAR(30),
- );
Q. What is the purpose of DML Language?
Ans:- Data manipulation language makes the user able to retrieve and manipulate data in a relational database. The DML commands can only perform read-only operations on data. We can perform the following operations using DDL language:
- Insert data into the database through the INSERT command.
- Retrieve data from the database through the SELECT command.
- Update data in the database through the UPDATE command.
- Delete data from the database through the DELETE command.
Example
- INSERT INTO Student VALUES (111, ‘George’, ‘Computer Science’)
Q. What is the purpose of DCL Language?
Ans:- Data control language allows users to control access and permission management to the database. It is the subset of a database, which decides that what part of the database should be accessed by which user at what point of time. It includes two commands, GRANT and REVOKE.
GRANT: It enables system administrators to assign privileges and roles to the specific user accounts to perform specific tasks on the database.
REVOKE: It enables system administrators to revoke privileges and roles from the user accounts so that they cannot use the previously assigned permission on the database.
Example
- GRANT * ON mydb.Student TO javatpoint@localhsot;
Q. What are tables and fields in the database?
Ans:- A table is a set of organized data in the form of rows and columns. It enables users to store and display records in the structured format. It is similar to worksheets in the spreadsheet application. Here rows refer to the tuples, representing the simple data item, and columns are the attribute of the data items present in a particular row. Columns can categorize as vertical, and Rows are horizontal.
Fields are the components to provide the structure for the table. It stores the same category of data in the same data type. A table contains a fixed number of columns but can have any number of rows known as the record. It is also called a column in the table of the database. It represents the attribute or characteristics of the entity in the record.
Example
Table: Student
Field: Stud_rollno, Stud_name, Date of Birth, Branch, etc.
Q. What is a unique key?
Ans:- A unique key is a single or combination of fields that ensure all values stores in the column will be unique. It means a column cannot stores duplicate values. This key provides uniqueness for the column or set of columns. For example, the email addresses and roll numbers of student’s tables should be unique. It can accept a null value but only one null value per column. It ensures the integrity of the column or group of columns to store different values into a table.
We can define a foreign key into a table as follows:
- CREATE TABLE table_name(
- col1 datatype,
- col2 datatype UNIQUE,
- …
- );
Python
| What is the procedure to count the number of times a given value appears in an array of integers? You can count the number of times a given value appears using the bincount() function. It should be noted that the bincount() function accepts positive integers or boolean expressions as its argument. Negative integers cannot be used. Use NumPy.bincount(). The resulting array is>>> arr = NumPy.array([0, 5, 4, 0, 4, 4, 3, 0, 0, 5, 2, 1, 1, 9])>> NumPy.bincount(arr) What are the significant features of the pandas Library? Ans :- The key features of the panda’s library are as follows:Memory EfficientData AlignmentReshapingMerge and joinTime Series |
Case Study
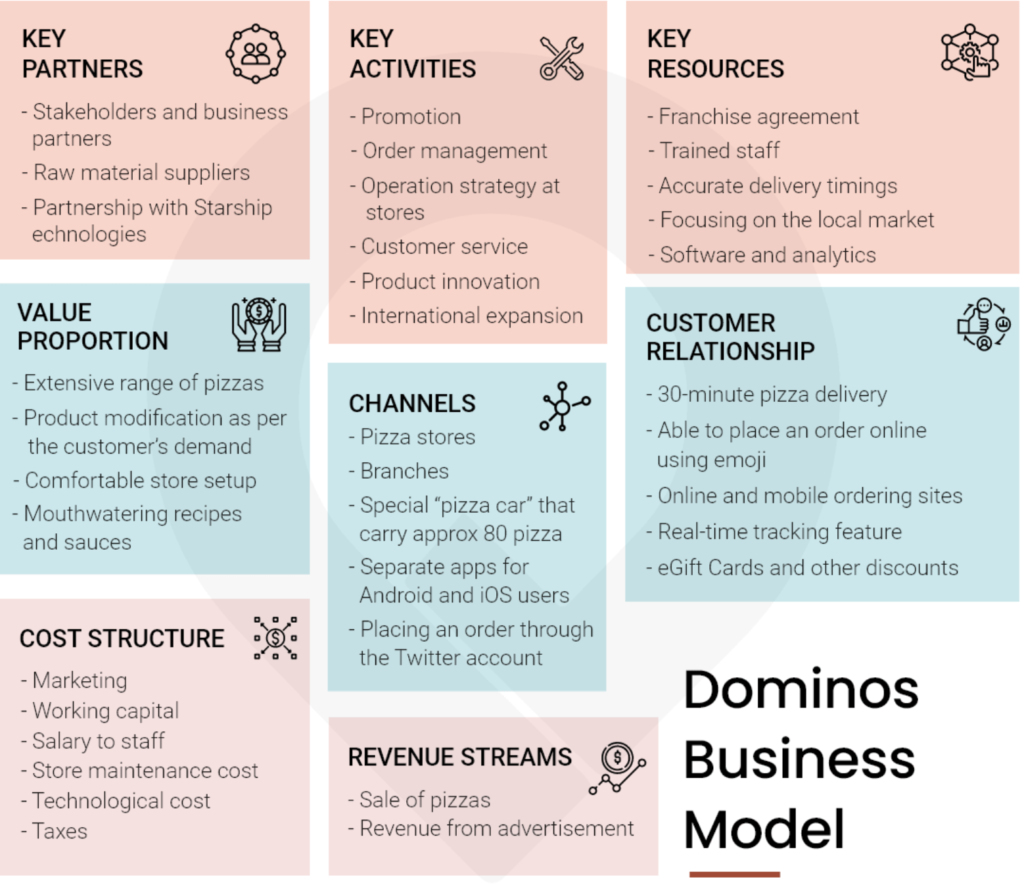
Q. Talk about everything about Domino’s business model. Emphasize more on cost structure, revenue model, customer relationship, and all the verticals that account for Domino’s growth
Big Data
Q. Explain some important features of Hadoop.
Ans: Hadoop supports the storage and processing of big data. It is the best solution for handling big data challenges. Some important features of Hadoop are –
- Open Source – Hadoop is an open source framework which means it is available free of cost. Also, the users are allowed to change the source code as per their requirements.
- Distributed Processing – Hadoop supports distributed processing of data i.e. faster processing. The data in Hadoop HDFS is stored in a distributed manner and MapReduce is responsible for the parallel processing of data.
- Fault Tolerance – Hadoop is highly fault-tolerant. It creates three replicas for each block at different nodes, by default. This number can be changed according to the requirement. So, we can recover the data from another node if one node fails. The detection of node failure and recovery of data is done automatically.
- Reliability – Hadoop stores data on the cluster in a reliable manner that is independent of machine. So, the data stored in Hadoop environment is not affected by the failure of the machine.
- Scalability – Another important feature of Hadoop is the scalability. It is compatible with the other hardware and we can easily ass the new hardware to the nodes.
- High Availability – The data stored in Hadoop is available to access even after the hardware failure. In case of hardware failure, the data can be accessed from another path.
Statistics
Q. What is the meaning of selection bias and types of selection bias?
Ans:- Selection bias is a phenomenon that involves the selection of individual or grouped data in a way that is not considered to be random. Randomization plays a key role in performing analysis and understanding model functionality better.
If correct randomization is not achieved, then the resulting sample will not accurately represent the population.
There are many types of selection bias as shown below:
- Observer selection
- Attrition
- Protopathic bias
- Time intervals
- Sampling bias
The Data Monk Interview Books – Don’t Miss
Now we are also available on our website where you can directly download the PDF of the topic you are interested in. On Amazon, each book costs ~299, on our website we have put it at a 60-80% discount. There are ~4000 solved interview questions prepared for you.
10 e-book bundle with 1400 interview questions spread across SQL, Python, Statistics, Case Studies, and Machine Learning Algorithms – Ideal for 0-3 years experienced candidates
23 E-book with ~2000 interview questions spread across AWS, SQL, Python, 10+ ML algorithms, MS Excel, and Case Studies – Complete Package for someone between 0 to 8 years of experience (The above 10 e-book bundle has a completely different set of e-books)
12 E-books for 12 Machine Learning algorithms with 1000+ interview questions – For those candidates who want to include any Machine Learning Algorithm in their resume and to learn/revise the important concepts. These 12 e-books are a part of the 23 e-book package
Individual 50+ e-books on separate topics
Important Resources to crack interviews (Mostly Free)
There are a few things that might be very useful for your preparation
The Data Monk Youtube channel – Here you will get only those videos that are asked in interviews with Data Analysts, Data Scientists, Machine Learning Engineers, Business Intelligence Engineers, Analytics managers, etc.
Go through the watchlist which makes you uncomfortable:-
Complete Python Playlist for Data Science
Company-wise Data Science Interview Questions – Must Watch
All important Machine Learning Algorithm with code in Python
Complete Python Numpy Playlist
Complete Python Pandas Playlist
Case Study and Guesstimates Complete Playlist
Complete Playlist of Statistics
Keep Learning !!
Thanks,