Hey, The Data Monk Fellas!
We are back for you with yet another topic in Python. Today we will be discussing “splitting data set in Python”. Follow this tutorial thoroughly to get a complete overview of this significant topic in the discipline of ML. So, before we dive into the procedure of splitting data set in Python, it is cardinal to know why we actually need to do so.
Basically, for most of the problems in ML, we train a model to learn from the given data and then test its performance on some data. These two types of data are respectively known as training and test sets.

Alright, let’s pick an example to see what train and test sets really mean.
Say, you have some data which looks like this:
| TOTAL AREA | FLOORS | CARPET AREA | PRICE |
| 112 | 3 | 90 | 500000 |
| 230 | 4 | 100 | 1000000 |
| 290 | 3 | 150 | 2000000 |
*The table above is just a preview. Actual data may have 10000 rows.
We need to predict the price of certain houses in Manhattan using their features like total area, floors and carpet area.
So, we begin collecting the data. After collecting, we have the total area, floors and carpet area of different houses and the prices corresponding to these houses. This is our data set.
After this we build a model. For this, we need to split(divide) this dataset in a certain ratio so that our model can learn from a fraction of data and we could analyse its performance from the rest of that data. So, out of the data of 10000 houses, I split the data set in such a way that 8000 rows are used for training and 2000 are used for testing. To do so, we can write some lines of code on our own or simply use an available Python function. Let’s consider the code below to understand:
Firstly, download the dataset here:
Linear_x_train.csv
https://www.dropbox.com/s/z82u1qpibiju3pw/Linear_X_Train.csv?dl=0
Linear_y_train.csv
https://www.dropbox.com/s/20m1w0yummyskrc/Linear_Y_Train.csv?dl=0
When your dataset is downloaded, do as instructed below:
Import pandas as follows:

Now, type in the code displayed below:
Import the data as a Pandas dataframe.

Now, see below-
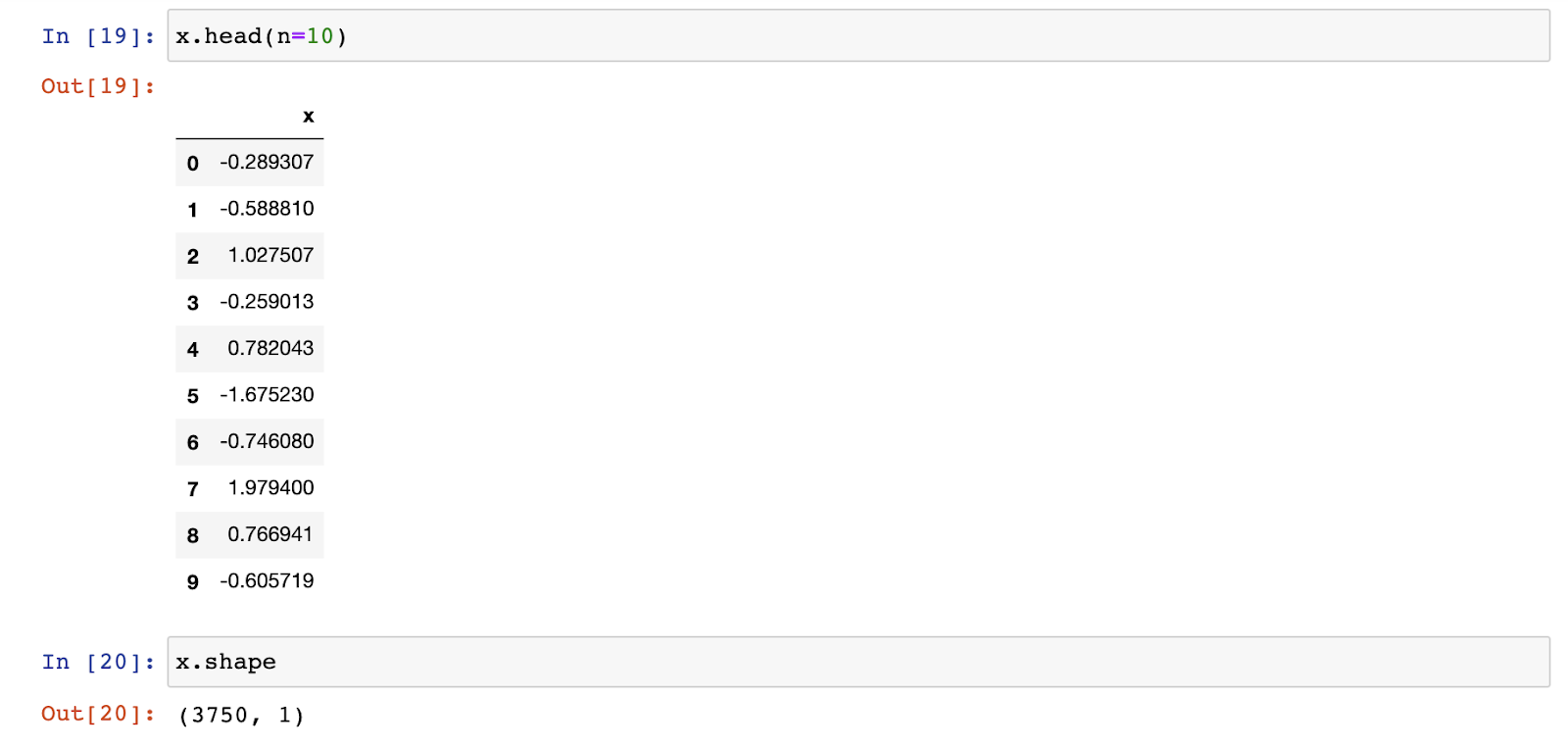
For the purpose of demonstrating the splitting process, we have taken a sample dataset. It consists of 3750 rows and 1 column. Thus, the shape as shown above, is (3750,1).
Now, repeat the steps above with the second file i.e. Linear_y_train.csv

In y, we have the labels corresponding to the x values.
Let’s come to the main point now. First off, we will show you how to split this dataset into training and testing data using two techniques:
- Custom
- Using sklearn
Method 1
Suppose I wish to use 70% of the data set for training my model and 30% of the data for testing it, here is the code I will write:
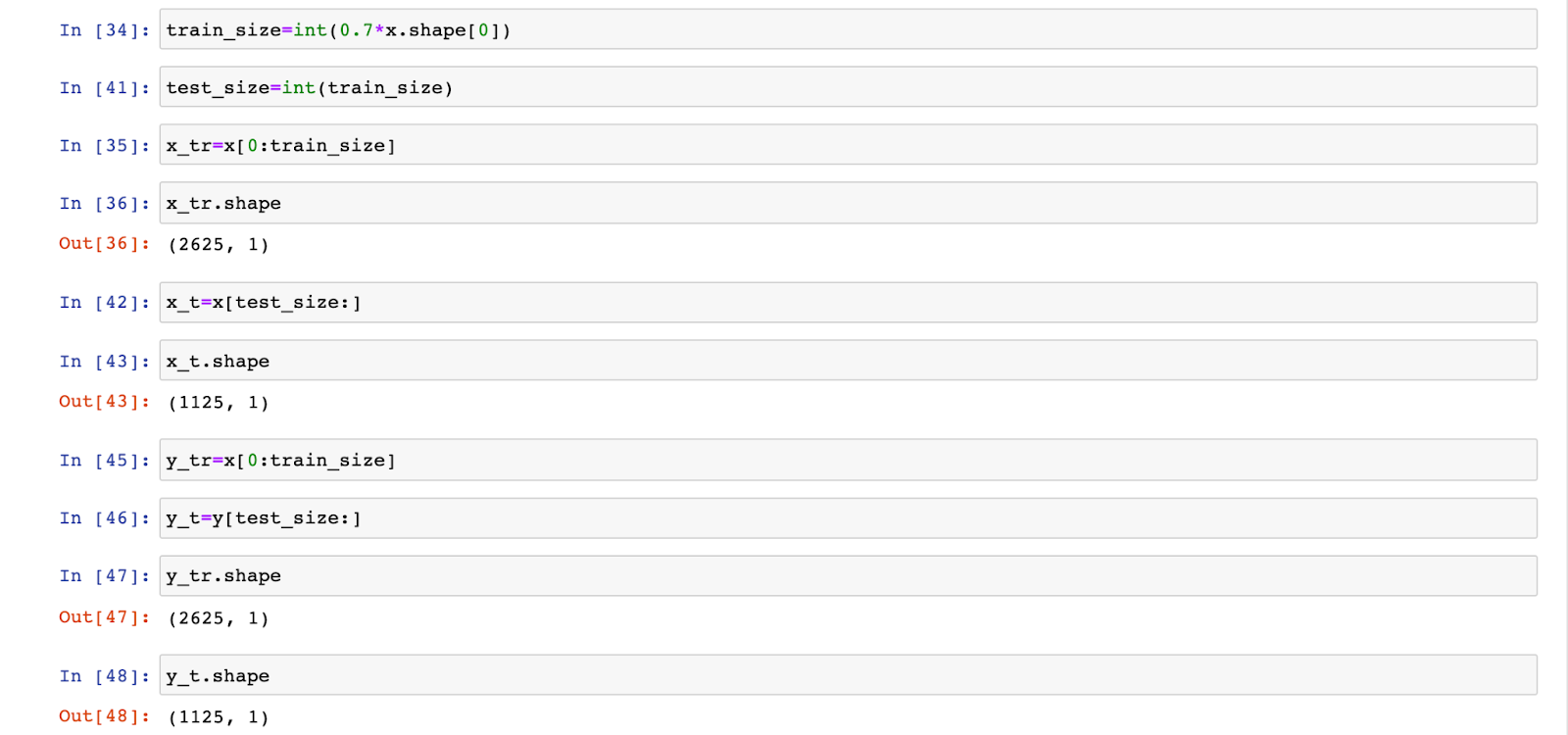
Here, the train set size is defined as 70% of the dataset size. So we slice the data such that:
- 70% rows come into train set
- Rest, 30% come into test set
So, train set size=2625 and test set size= 1125.
Then, we repeated the same steps with the set of labels. (Shown above)
Method 2
Now, we will use the sklearn library to import a function called train_test_split, which reduces all the code to just a single line!
See the code below:
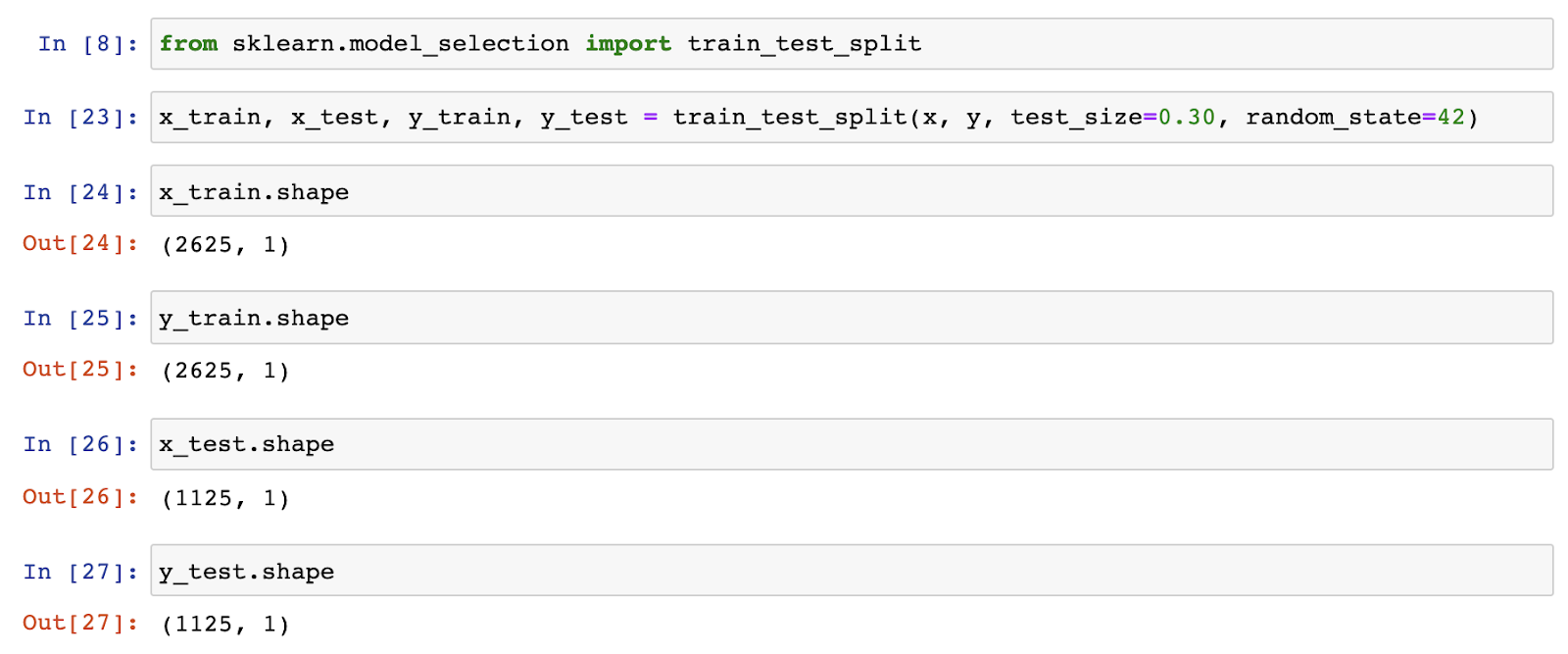
Note that in code cell [23], we split the dataset into train and test by providing the dataset x and y as the first two parameters. Followed by the test-size 30%, which implies that the train set size is 70 %. We also specify the random state, which is a parameter of train_test_split that allows us to fix seeds for shuffling the data.
As it can be observed, we get the train set size=2625 and test set size= 1125, which is exactly similar to the custom code we created above. But see how our task is significantly reduced to just a line which does everything and we no longer need to do it separately for the x data and labels. This is the power of libraries!
Alright data monks! We highly recommend that you practice train test splitting on a new dataset, using both the methods we discussed today. Test your knowledge here:
https://thedatamonk.com/question/try-splitting/
See you with a fresh topic next time. Goodbye!
The Data Monk Interview Books – Don’t Miss
Now we are also available on our website where you can directly download the PDF of the topic you are interested in. At Amazon, each book costs ~299, on our website we have put it at a 60-80% discount. There are ~4000 solved interview questions prepared for you.
10 e-book bundle with 1400 interview questions spread across SQL, Python, Statistics, Case Studies, and Machine Learning Algorithms – Ideal for 0-3 years experienced candidates
23 E-book with ~2000 interview questions spread across AWS, SQL, Python, 10+ ML algorithms, MS Excel, and Case Studies – Complete Package for someone between 0 to 8 years of experience (The above 10 e-book bundle has a completely different set of e-books)
12 E-books for 12 Machine Learning algorithms with 1000+ interview questions – For those candidates who want to include any Machine Learning Algorithm in their resume and to learn/revise the important concepts. These 12 e-books are a part of the 23 e-book package
Individual 50+ e-books on separate topics
Important Resources to crack interviews (Mostly Free)
There are a few things which might be very useful for your preparation
The Data Monk Youtube channel – Here you will get only those videos that are asked in interviews for Data Analysts, Data Scientists, Machine Learning Engineers, Business Intelligence Engineers, Analytics Manager, etc.
Go through the watchlist which makes you uncomfortable:-
All the list of 200 videos
Complete Python Playlist for Data Science
Company-wise Data Science Interview Questions – Must Watch
All important Machine Learning Algorithm with code in Python
Complete Python Numpy Playlist
Complete Python Pandas Playlist
SQL Complete Playlist
Case Study and Guesstimates Complete Playlist
Complete Playlist of Statistics