Ridge and LASSO are two important regression models which comes handy when Linear Regression fails to work.
This topic needed a different mention without it’s important to understand COST function and the way it’s calculated for Ridge,LASSO, and any other model.
Let’s first understand the cost function
Cost function is the amount of damage you are going to incur if your prediction goes wrong.
In the layman’s term, suppose you run a pizza shop and you are predicting some values for the number of pizzas sold in the coming 12 months. There would definitely be a delta between the actual and predicted value in your ‘Testing data set’, right?
This is denoted by
Sum of Square of Errors = |predicted-actual|^2
i.e. there is 0 loss when you hit the correct prediction, but there is always
a loss whenever there is a variance.
This is your basic definition of cost function.
Linear, LASSO, Ridge, xyz, every algorithm tries to reduce the penalty i.e. Cost function score
When we talk about Ridge regression, it involves one more point in the above mentioned cost function
Ridge regression C.F. = Sum of Square of Error (SSE)
= |predicted-actual|^2 + lambda*(Beta)^2
The bold part represents L2 Regularization
LASSO Regression C.F. = Sum of Square of Error(SSE)
= |predicted-actual|^2 + lambda*Beta
The bold part represents L1 Regularization
Elastic Net Regression =
|predicted-actual|^2+[(1-alpha)*Beta^2+alpha*Beta]
when alpha = 0, the Elastic Net model reduces to Ridge, and when it’s 1, the model becomes LASSO, other than these values the model behaves in a hybrid manner.
V.V.I. Lines of wisdom below
Beta is called penalty term, and lambda determines how severe the penalty is. And Beta is nothing but the slope of the linear regression line.
So you can see that we are increasing the SSE by adding penalty term, this way we are making the present model worse by ourself 😛
The only difference between L1 and L2 Regularisation or Ridge and LASSO Regression is the cost function. And the difference itself is quite evident i.e. (Beta)^2 vs Beta
You already know what alpha is, right? The Prediction variance square
Now lambda is the
LASSO – Lease Absolute Shrinkage and Selection Operator
Why do we need any other regression model?
Say, you have two points in a co-ordinate (assume these two points as your training dataset i.e. only two data points in your training dataset), you can easily draw a line passing through these two line.
A linear regression does the same, but now if you have to test this LR with 7 data points in your test dataset. Take a look at the diagram below
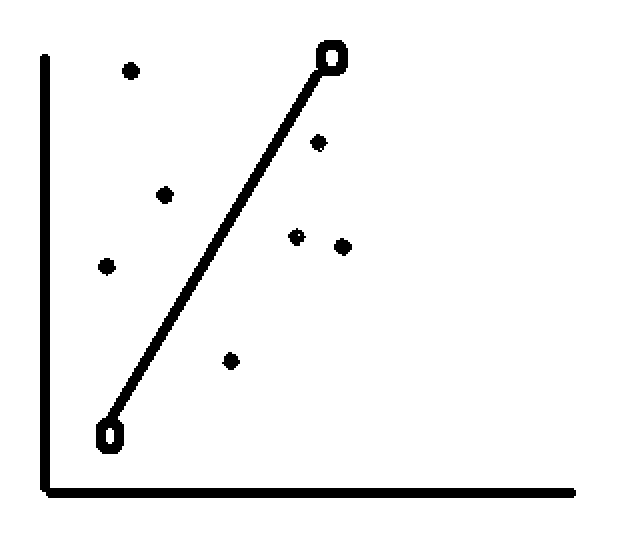
in the above pic, two circle represents the two data points in the training dataset for your LR model, now this model has perfect accuracy on training dataset, but in testing dataset you have 7 different variables where your model will suffer with a large amount of prediction error.
Prediction error is nothing but the perpendicular distance between predicted and actual.
In this case, other regression comes to the rescue by changing the cost function.
Remember, till now cost function was just the Sum of Square of the difference between predicted and actual, correct?
Now we modify the line of regression in such a way that it is less accurate on training dataset but gives a better result in test dataset. Basically we compromised with the accuracy in the training dataset.
Now the line looks something like the one below
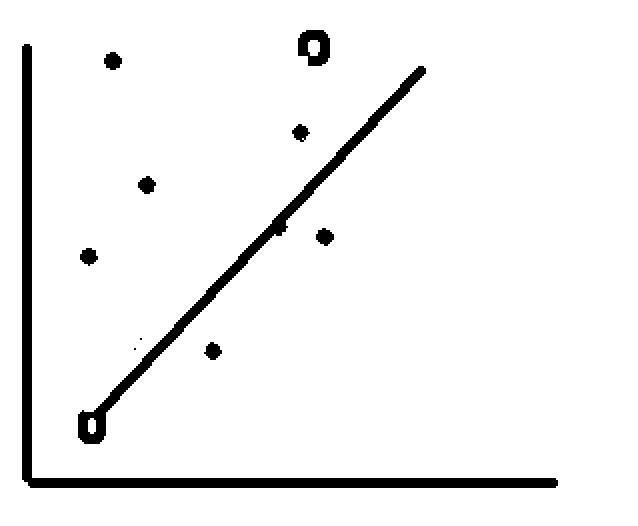
Now we know that we need to reduce the training model’s accuracy, but How do we lose model’s accuracy?
By reducing the coefficient value of the features learnt while creating the model. Iterating the same as mentioned above
Beta is called penalty term, and lambda determines how severe the penalty is. And Beta is nothing but the slope of the linear regression line.
So you can see that we are increasing the SSE by adding penalty term
The key difference between these techniques is that Lasso shrinks the less important feature’s coefficient to zero thus, removing some feature altogether. So, this works well for feature selection in case we have a huge number of features.
The Lasso method on its own does not find which features to shrink. Instead, it is a combination of Lasso and Cross Validation (CV) which allows us to determine the best Lasso parameter.
These regression helps reduce variance by shrinking parameters and making our prediction more sensitive to them.
Remember, when you have less data points, your training dataset in Linear Regression might show a good accuracy, but not a good prediction on the testing dataset. In that case do try Ridge, LASSO, and Elastic Net regression.
We will soon be publishing an article containing complete code covering all these algorithms via a Hackathon solution or on a open source dataset.
Post your questions, if you have any
Keep Learning 🙂
The Data Monk
The Data Monk services
We are well known for our interview books and have 70+ e-book across Amazon and The Data Monk e-shop page . Following are best-seller combo packs and services that we are providing as of now
- YouTube channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel - Website – ~2000 completed solved Interview questions in SQL, Python, ML, and Case Study
Link – The Data Monk website - E-book shop – We have 70+ e-books available on our website and 3 bundles covering 2000+ solved interview questions. Do check it out
Link – The Data E-shop Page - Instagram Page – It covers only Most asked Questions and concepts (100+ posts). We have 100+ most asked interview topics explained in simple terms
Link – The Data Monk Instagram page - Mock Interviews/Career Guidance/Mentorship/Resume Making
Book a slot on Top Mate
The Data Monk e-books
We know that each domain requires a different type of preparation, so we have divided our books in the same way:
1. 2200 Interview Questions to become Full Stack Analytics Professional – 2200 Most Asked Interview Questions
2.Data Scientist and Machine Learning Engineer -> 23 e-books covering all the ML Algorithms Interview Questions
3. 30 Days Analytics Course – Most Asked Interview Questions from 30 crucial topics
You can check out all the other e-books on our e-shop page – Do not miss it
For any information related to courses or e-books, please send an email to nitinkamal132@gmail.com