Most Asked Pandas Questions
Welcome to the 4th Part of Most Asked Pandas Questions. Here we have already covered 30 most asked questions in Pandas. Go through all the questions below and if possible, practice them in your system.
Comment below if you have any other use case or question on Pandas

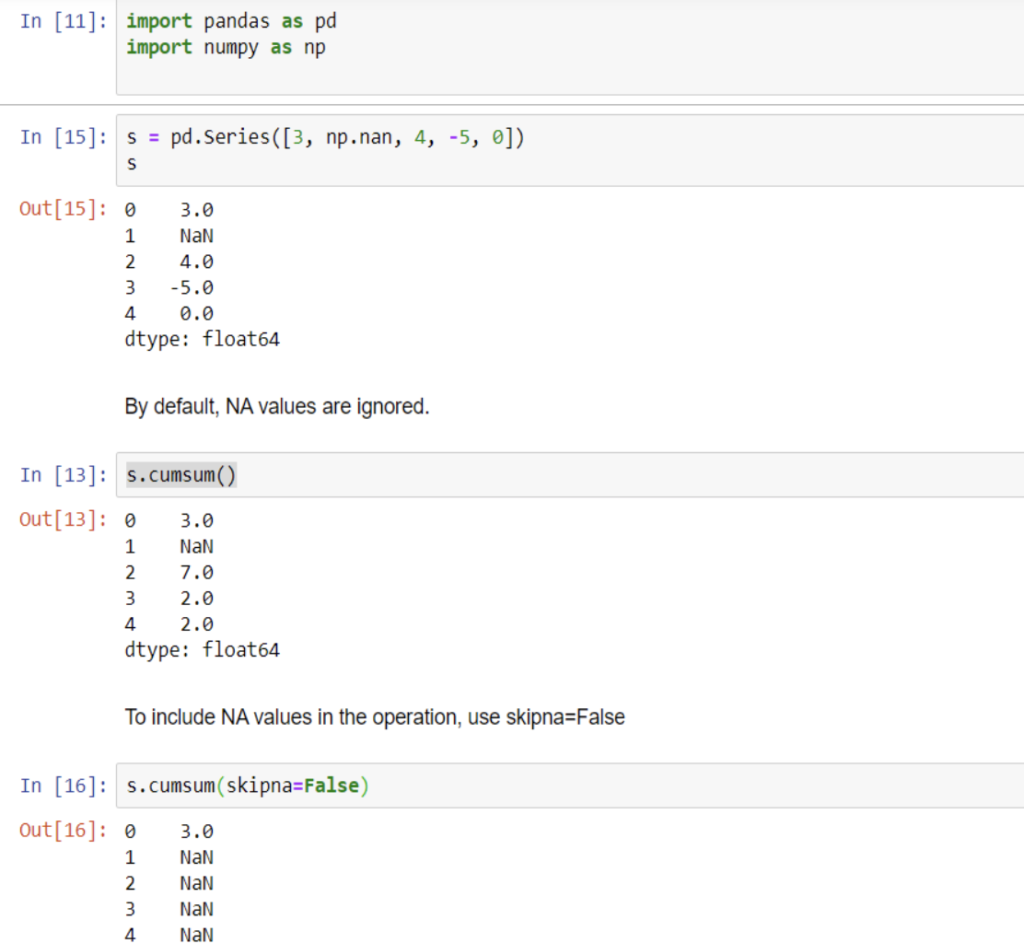
30. What is Cumsum() Function in Pandas and why do we use it ?
The Cumsum() Function is used to get Cumulative Sum over the dataframe.
Let’s understand with a practical example.
Microsoft Word – Final_Pandas_Neha.docx
import pandas as pd
import numpy as np
s = pd.Series([3, np.nan, 4, -5, 0])
s.cumsum()
s.cumsum(skipna=False)
31 What is Pandas ml?
Pandas_ml is a package which integrates pandas , scikit-learn , xgboost into one package for easy handling of data and creation of machine learning models.
Installation:
pip install pandas-ml
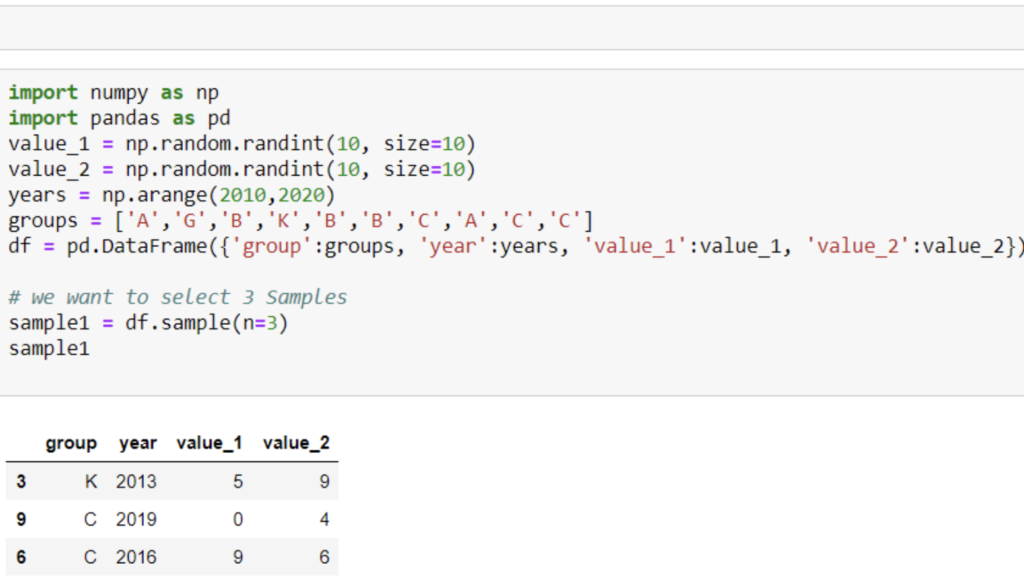
32. What is Sample Method in Pandas?
Sample Method is very useful when we want to select a random sample from a distribution. Sample Method allows you to Select random number of Samples from the Series or DataFrame.
Let‘s suppose this is our Dataframe.
import numpy as np
import pandas as pd
value_1 = np.random.randint(10, size=10)
value_2 = np.random.randint(10, size=10)
years = np.arange(2010,2020)
groups = [‘A’,’G’,’B’,’K’,’B’,’B’,’C’,’A’,’C’,’C’]
df = pd.DataFrame({‘group’:groups, ‘year’:years, ‘value_1’:value_1, ‘value_2’:value_2})
print(df)
sample1 = df.sample(n=3) sample1
33. What is loc and iloc function in Pandas?
loc : loc is label-based , which means that we have to specify the name of rows and columns that we want to filter out.
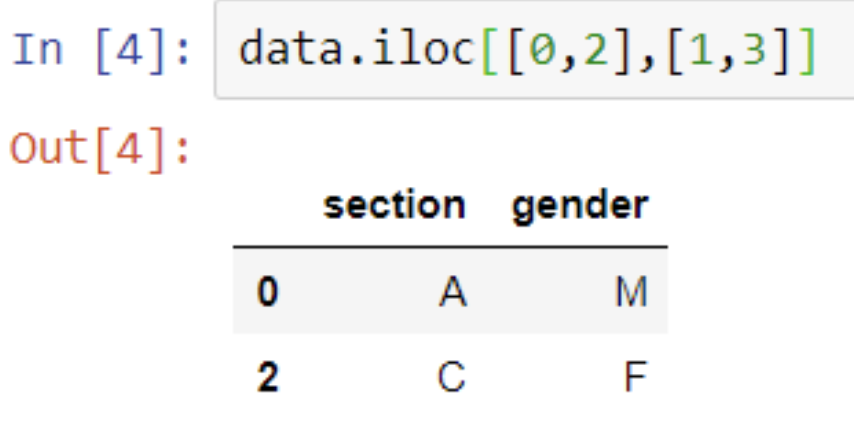
iloc : iloc is interger, index-based, we have to specify the rows and columns by their interger index.
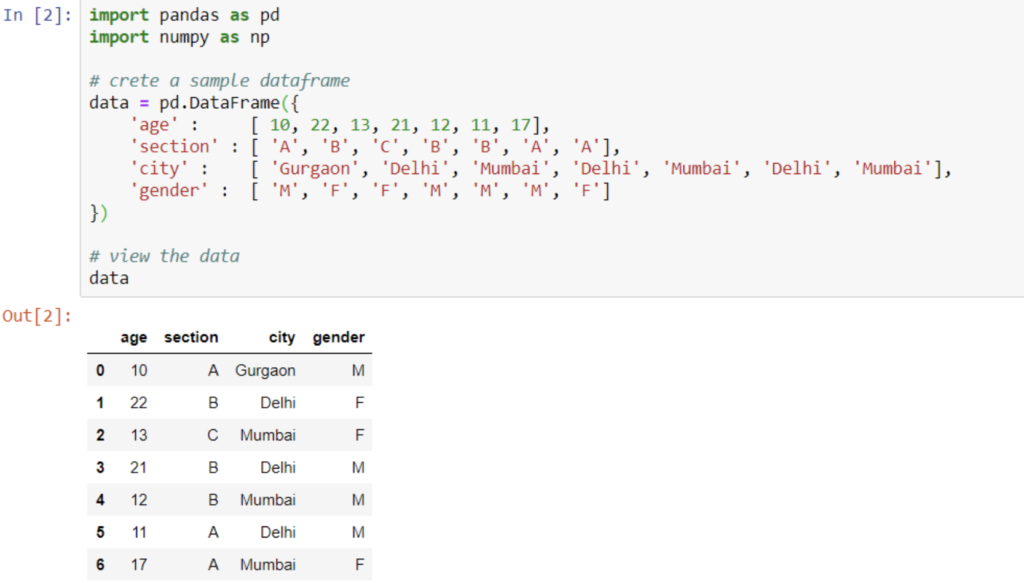
Let suppose this is our dataframe:
import pandas as pd
import numpy as np
# create a sample dataframe
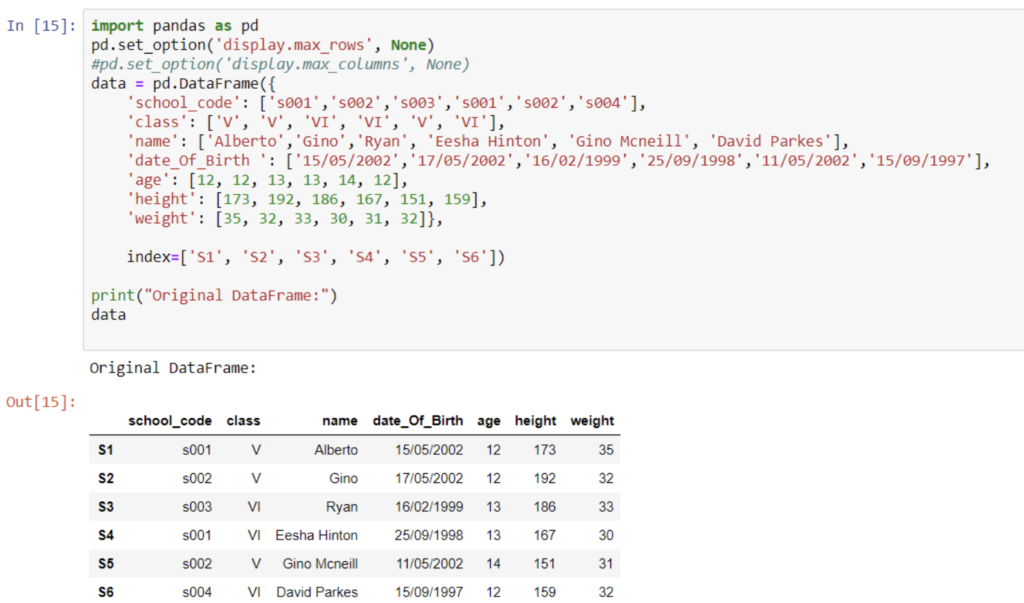
data = pd.DataFrame({
‘age’ : [ 10, 22, 13, 21, 12, 11, 17],
‘section’ : [ ‘A’, ‘B’, ‘C’, ‘B’, ‘B’, ‘A’, ‘A’],
‘city’ : [ ‘Gurgaon’, ‘Delhi’, ‘Mumbai’, ‘Delhi’, ‘Mumbai’, ‘Delhi’, ‘Mumbai’], ‘gender’ : [ ‘M’, ‘F’, ‘F’, ‘M’, ‘M’, ‘M’, ‘F’]
})
# view the data data
iloc Function:
# Select rows with particular indices and particular columns
data.iloc[[0,2],[1,3]]
loc Function :
# Select using loc Function
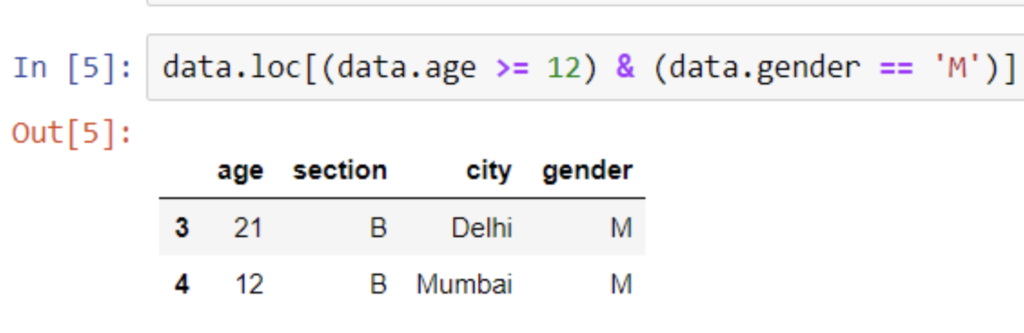
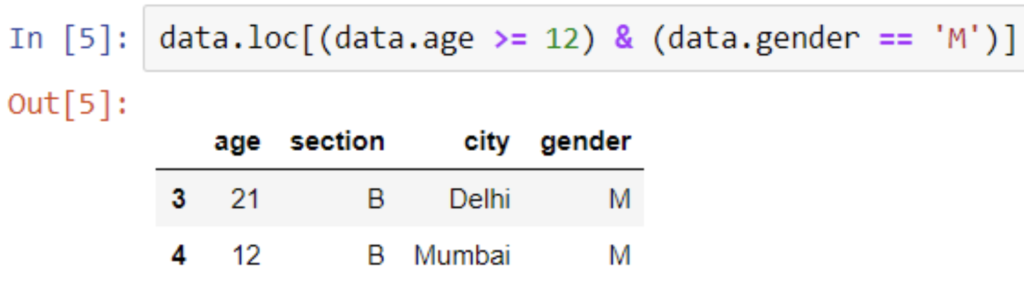
data.loc[(data.age >= 12) & (data.gender == ‘M’)]
34. What is Memory_usage function in Pandas ?
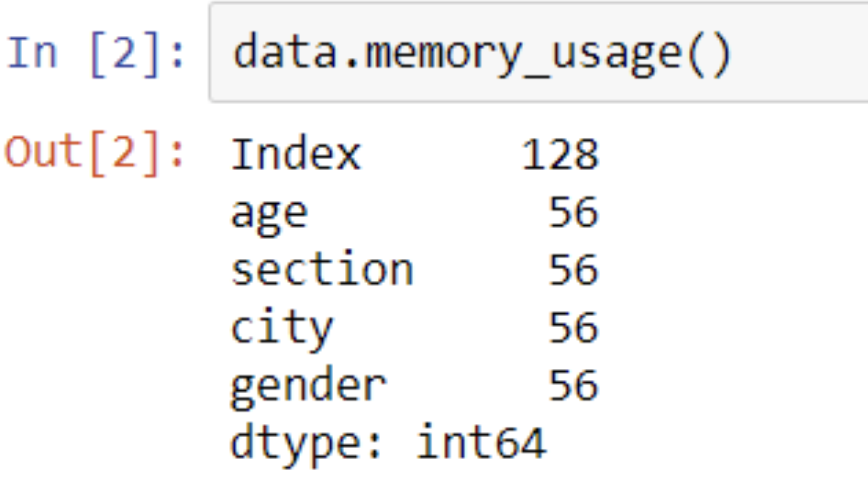
Memory_usage() returns how much memory each column uses in bytes. It is very useful when we are working with large dataframes.
data.memory_usage()
35. What is Group by function in Pandas and write a pandas program to split the dataframe into groups based on college code.
print(‘\nSplit the said data on school_code wise:’)
result = data.groupby([‘school_code’])
for name,group in result:
print(“\nGroup:”)
print(name) print(group) print(‘\n’)
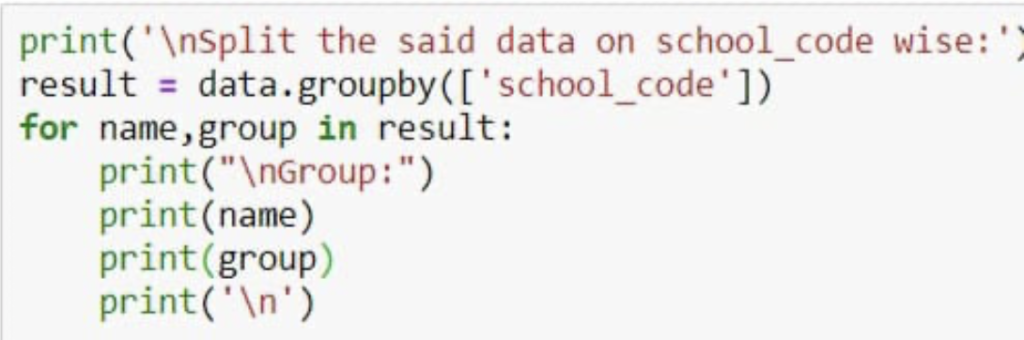
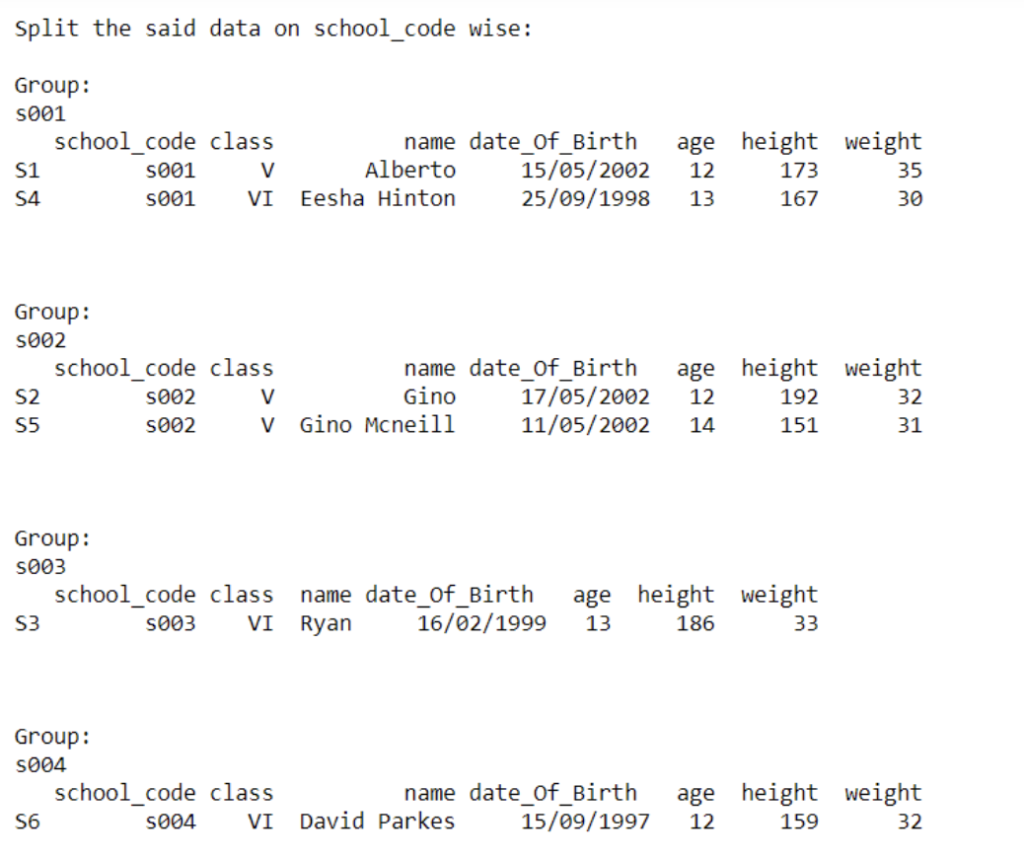
36. Write a Pandas program to split the following dataframe into group based on school_code and get min , max and mean value of age for each school ?
print(‘\nMean , min, and max value of age for each value of the school:’)
group = data.groupby(‘school_code’).agg({‘age’: [‘mean’, ‘min’, ‘max’]})
group
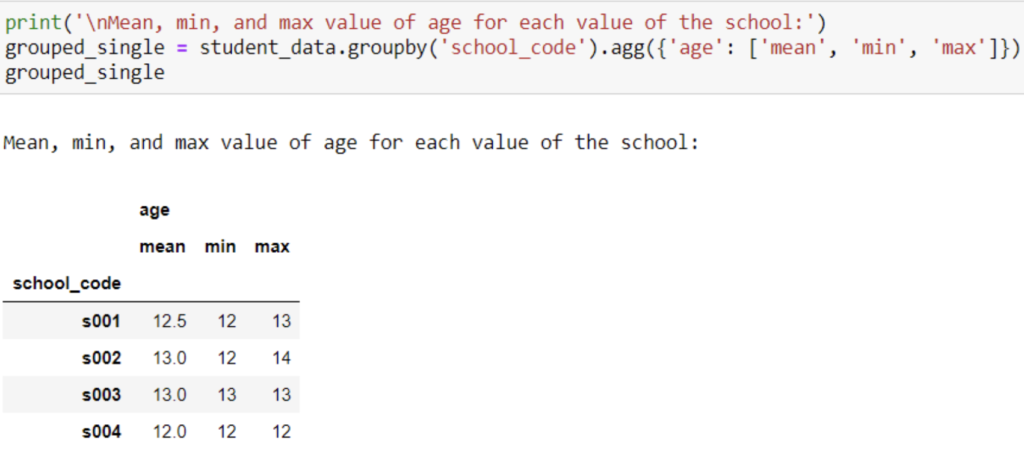
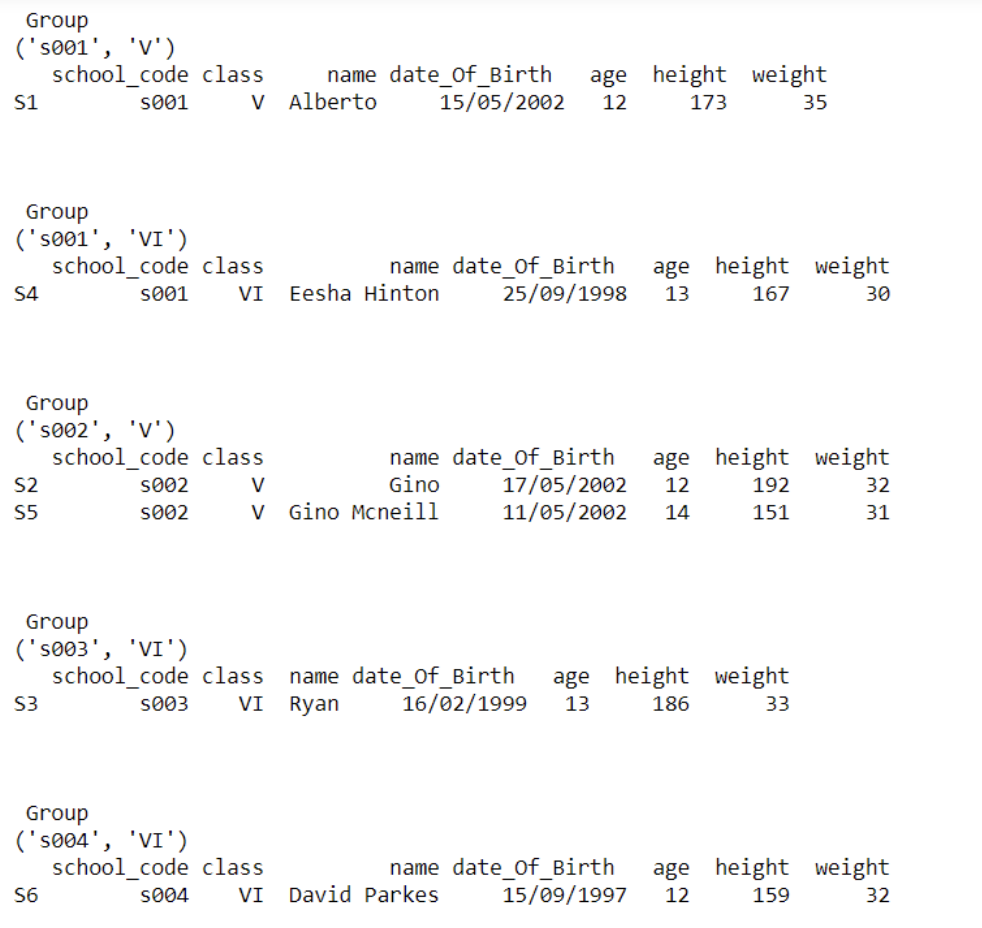
37. Write a Pandas Program to split the dataframe into group based on school_code and class.
Code :
result=data.groupby([‘school_code’,’class’])
for name,group in result:
print(‘\n Group’)
print(name)
print(group)
print(‘\n’)
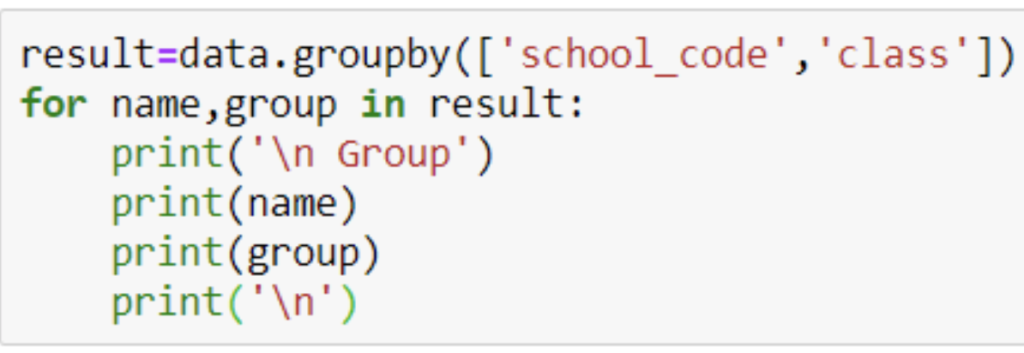
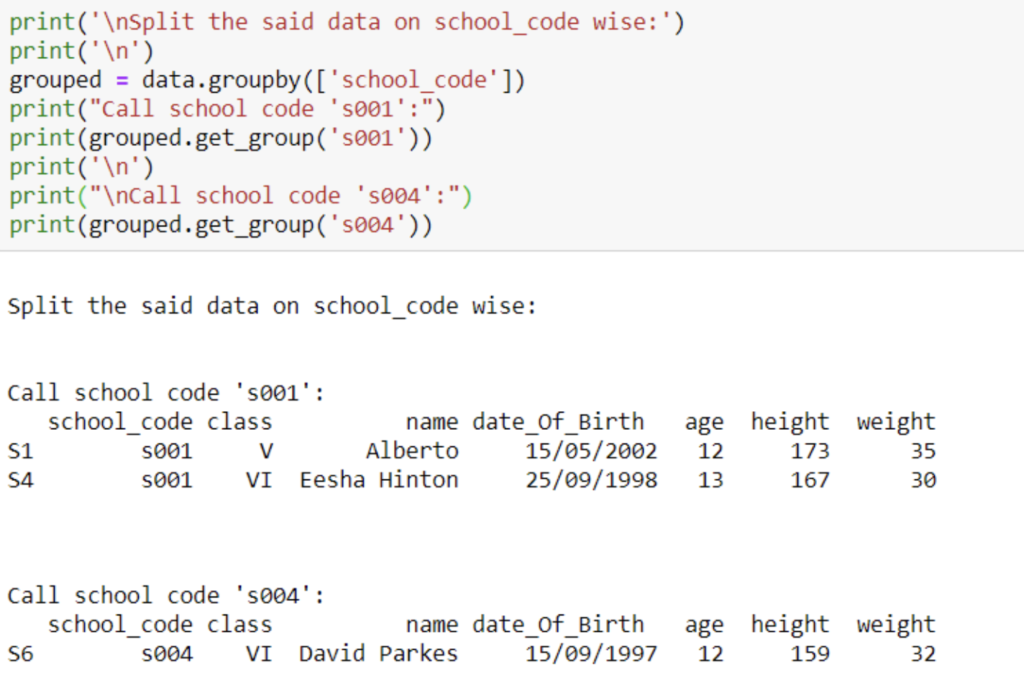
38. Write a Pandas program to split a dataframe into group based on school_code and call a specific group with the name.
There is a function called get_group() in the pandas with the help of which we can call any particular group from the dataframe.
Code :
print(‘\nSplit the said data on school_code wise:’) grouped = data.groupby([‘school_code’]) print(“Call school code ‘s001’:”) print(grouped.get_group(‘s001’))
print(‘\n’)
print(“\nCall school code ‘s004’:”) print(grouped.get_group(‘s004’))
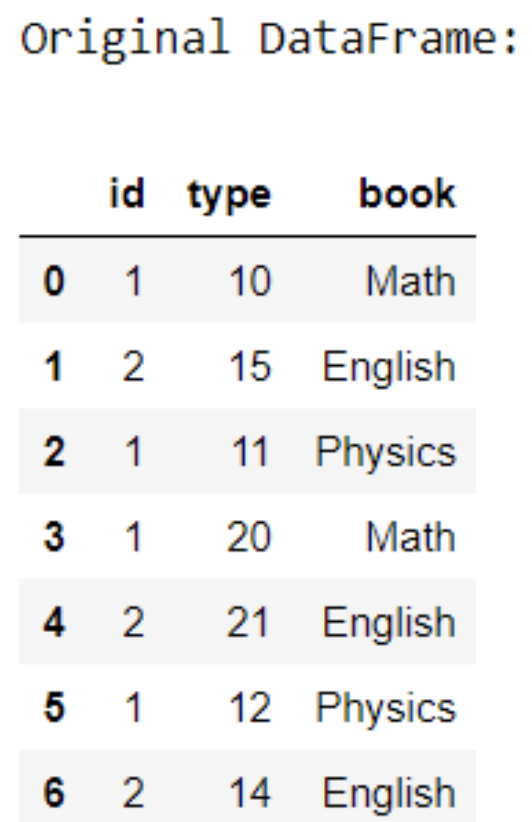
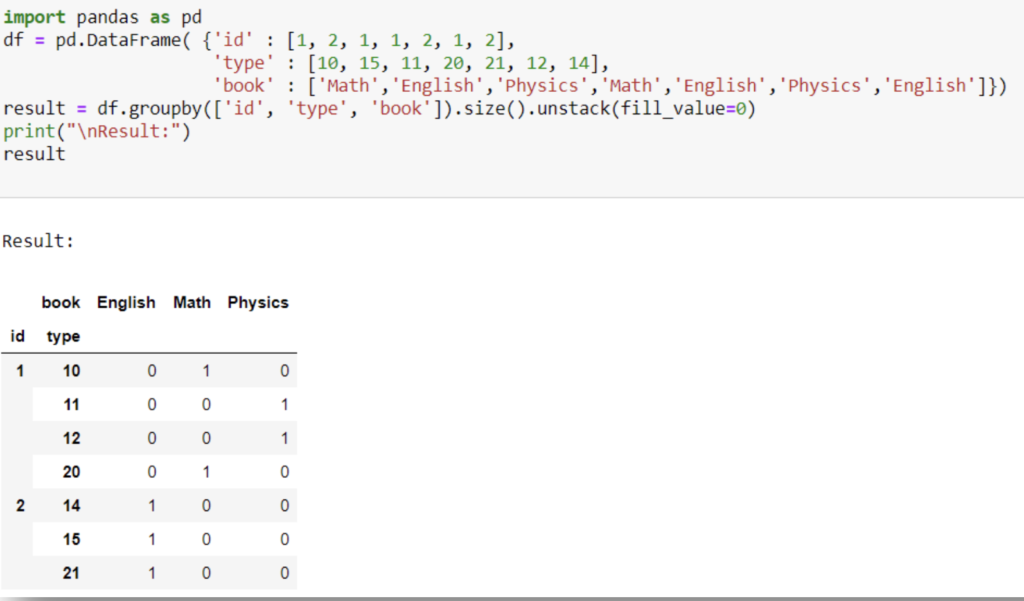
39. Write a Pandas program to split the dataframe into groups based on all columns and calculate value_counts of each subject.
Code :
import pandas as pd
df = pd.DataFrame( {‘id’ : [1, 2, 1, 1, 2, 1, 2],
‘type’ : [10, 15, 11, 20, 21, 12, 14],
‘book’ : [‘Math’,’English’,’Physics’,’Math’,’English’,’Physics’,’English’]})
print(“Original DataFrame:”)
result = df.groupby([‘id’, ‘type’, ‘book’]).size().unstack(fill_value=0)
print(“\nResult:”)
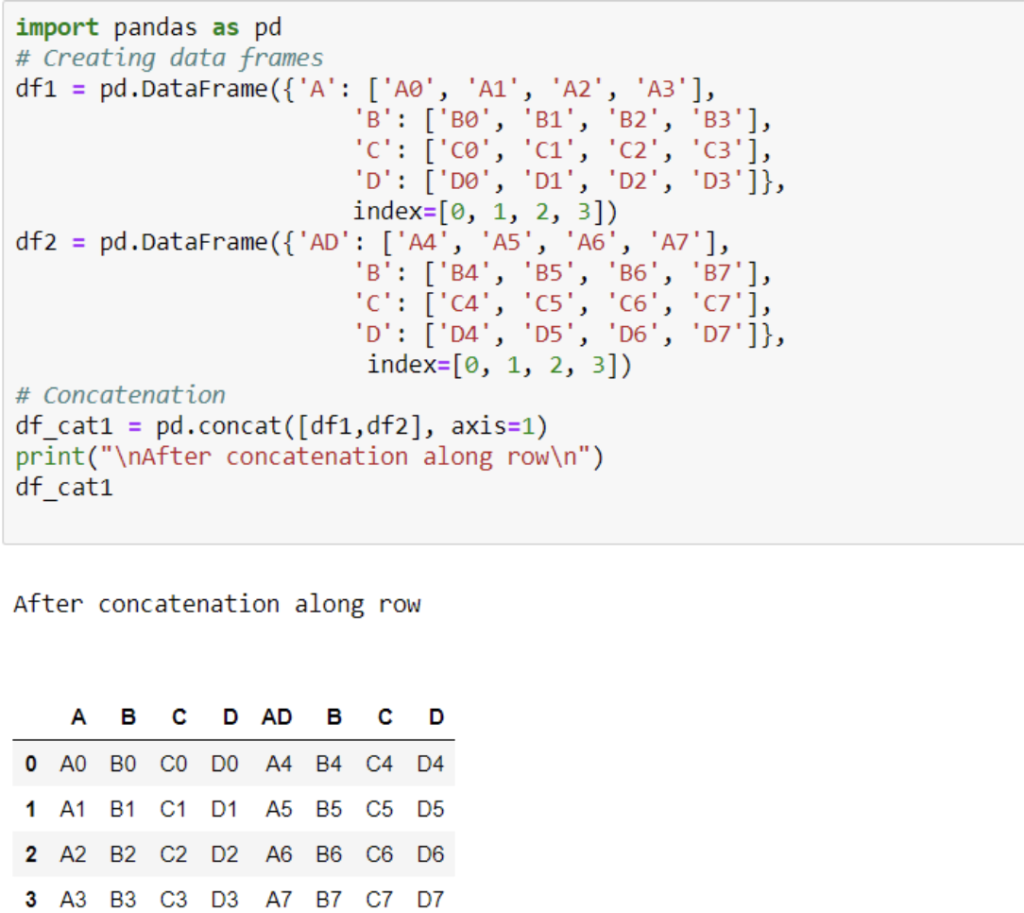
40. How to concatenate two or more than two dataframes. Explain with the help of Example.
We can concatenate two dataframes by using concat () function. Which is a inbuilt function of pandas library.
Let’s suppose we have 2 dataframes:
Microsoft Word – Final_Pandas_Neha.docx
# Creating data frames
df1 = pd.DataFrame({‘A’: [‘A0’, ‘A1’, ‘A2’, ‘A3’], ‘B’: [‘B0’, ‘B1’, ‘B2’, ‘B3’],
‘C’: [‘C0’, ‘C1’, ‘C2’, ‘C3’], ‘D’: [‘D0’, ‘D1’, ‘D2’, ‘D3’]}, index=[0, 1, 2, 3])
df2 = pd.DataFrame({‘AD’: [‘A4’, ‘A5’, ‘A6’, ‘A7’], ‘B’: [‘B4’, ‘B5’, ‘B6’, ‘B7’],
‘C’: [‘C4’, ‘C5’, ‘C6’, ‘C7’], ‘D’: [‘D4’, ‘D5’, ‘D6’, ‘D7’]},
index=[0, 1, 2, 3])
# Concatenation
df_cat1 = pd.concat([df1,df2], axis=1)
print(“\nAfter concatenation along row\n”) df_cat1
Thanks for going through the Most Asked Pandas Questions Part 4
The Data Monk Interview Books – Don’t Miss
Now we are also available on our website where you can directly download the PDF of the topic you are interested in. On Amazon, each book costs ~299, on our website we have put it at a 60-80% discount. There are ~4000 solved interview questions prepared for you.
10 e-book bundle with 1400 interview questions spread across SQL, Python, Statistics, Case Studies, and Machine Learning Algorithms – Ideal for 0-3 years experienced candidates
23 E-book with ~2000 interview questions spread across AWS, SQL, Python, 10+ ML algorithms, MS Excel, and Case Studies – Complete Package for someone between 0 to 8 years of experience (The above 10 e-book bundle has a completely different set of e-books)
12 E-books for 12 Machine Learning algorithms with 1000+ interview questions – For those candidates who want to include any Machine Learning Algorithm in their resume and to learn/revise the important concepts. These 12 e-books are a part of the 23 e-book package
Individual 50+ e-books on separate topics
Important Resources to crack interviews (Mostly Free)
There are a few things that might be very useful for your preparation
The Data Monk Youtube channel – Here you will get only those videos that are asked in interviews with Data Analysts, Data Scientists, Machine Learning Engineers, Business Intelligence Engineers, Analytics managers, etc.
Go through the watchlist which makes you uncomfortable:-
All the list of 200 videos
Complete Python Playlist for Data Science
Company-wise Data Science Interview Questions – Must Watch
All important Machine Learning Algorithm with code in Python
Complete Python Numpy Playlist
Complete Python Pandas Playlist
SQL Complete Playlist
Case Study and Guesstimates Complete Playlist
Complete Playlist of Statistics
Keep Learning !!
Thanks,