Feature selection methods in Model Building
When we deal with Big Data then there is a high chance of having a plethora of columns and rows in our dataset.
Selecting a group of columns is the crux of your model’s performance.
There are multiple methods for selecting columns from your table to build your model.
Feature selection methods are a group of process which aims at reducing the number of input variables while developing a predictive model.

Why do we need to reduce the number of input variable?
When you are creating a Machine Learning algorithm, your model will take ‘n’ number of variables to read and understand the behavior of the data.
These ‘n’ number of variables are your independent variables and the output variable is your dependent variable. While creating a model you need to have only those variables in your independent bucket which actually impacts the output/dependent variable.
Example – If you are trying to predict the salary of a person, then you probably do not need the menu of his breakfast.
In a dataset, there are 100s of columns and your target to pick only relevant parameters for your model. This is why we need a method to reduce the number of input variables in the model
This involves:
- Linear discrimination analysis – LDA is a way of reducing dimensionality which is used as a preprocessing step in Model building, prediction and classification problem
We start with the calculating the separability between different classes(i.e the distance between the mean of different classes). This is also called between-class variance. Here we take
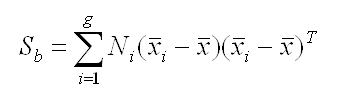
Then we look after the
distance between the mean and sample of each class, which is called the within-class variance
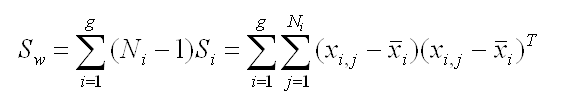
Third and the last step is to get the lower-dimensional space which takes the maximizes the between-class variance and minimizes the ‘within-class variance’
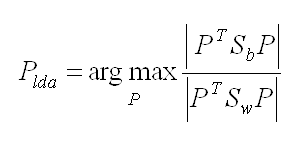
- ANOVA – A technique which comap
- Chi-Square
The best analogy for selecting features is “bad data in, bad answer out.” When we’re limiting or selecting the features, it’s all about cleaning up the data coming in.
Wrapper Methods
This involves:
- Forward Selection: We test one feature at a time and keep adding them until we get a good fit
- Backward Selection: We test all the features and start removing them to see what works better
- Recursive Feature Elimination: Recursively looks through all the different features and how they pair together
Wrapper methods are very labor-intensive, and high-end computers are needed if a lot of data analysis is performed with the wrapper method.
Explore these methods and if you know of some other method then do comment below
The Data Monk Interview Books – Don’t Miss
Now we are also available on our website where you can directly download the PDF of the topic you are interested in. At Amazon, each book costs ~299, on our website we have put it at a 60-80% discount. There are ~4000 solved interview questions prepared for you.
10 e-book bundle with 1400 interview questions spread across SQL, Python, Statistics, Case Studies, and Machine Learning Algorithms – Ideal for 0-3 years experienced candidates
23 E-book with ~2000 interview questions spread across AWS, SQL, Python, 10+ ML algorithms, MS Excel, and Case Studies – Complete Package for someone between 0 to 8 years of experience (The above 10 e-book bundle has a completely different set of e-books)
12 E-books for 12 Machine Learning algorithms with 1000+ interview questions – For those candidates who want to include any Machine Learning Algorithm in their resume and to learn/revise the important concepts. These 12 e-books are a part of the 23 e-book package
Individual 50+ e-books on separate topics
Important Resources to crack interviews (Mostly Free)
There are a few things which might be very useful for your preparation
The Data Monk Youtube channel – Here you will get only those videos that are asked in interviews for Data Analysts, Data Scientists, Machine Learning Engineers, Business Intelligence Engineers, Analytics Manager, etc.
Go through the watchlist which makes you uncomfortable:-
All the list of 200 videos
Complete Python Playlist for Data Science
Company-wise Data Science Interview Questions – Must Watch
All important Machine Learning Algorithm with code in Python
Complete Python Numpy Playlist
Complete Python Pandas Playlist
SQL Complete Playlist
Case Study and Guesstimates Complete Playlist
Complete Playlist of Statistics