So, I just started solving the latest Hackathon on Analytics Vidhya, Women in the loop . Be it a real-life Data Science problem or a Hackathon, one-hot encoding is one of the most important part of your data preparation.
If you don’t know about it yet, then you are definitely missing out on something which can boost your rank.
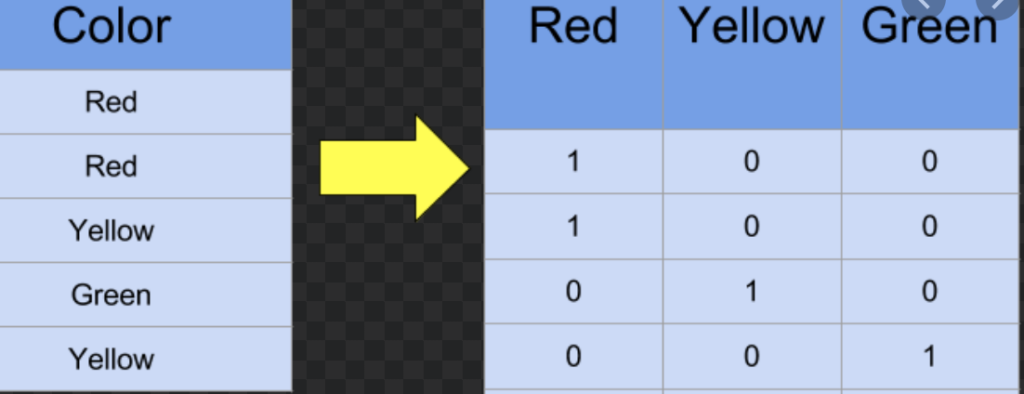
One hot encoding is a representation of categorical variables as binary vectors. What this means is that we want to transform a categorical variable or variables to a format that works better with classification and regression algorithms.
How not to do a categorical division?
Basically, if you have a column with Course Details like. Data Science, Software Development, Testing, etc. and you want to use these categorical variable in your model, then the best way to do is to make a column with binary variable with all the variables. So, you will have Data Science, Software Development, Testing will be new columns with values as 0, 1, 2, etc.
Now the problem is that 2>1>0 and the model might treat it as this way. So, to get things sorted you need to specify this to the model that ‘bro, these are all categorical numbers and you dare not treat it as numbers’
What to do?
Create new column as binary column. So, Data Science, Software Development, Testing, etc. with 0 and 1. This whole process is called One Hot Encoding.
Example below
There was some JSON error while directly posting the code, so pasting the screenshot


ohe <- c("Course_Domain","Course_Type")
train_data = as.data.frame(train_data)
Put the name of the variables which need OHE treatment at one place and convert the training_data into data framedummies_train = dummyVars(~ Course_Domain+Course_Type , data = train_data)
df_ohe = as.data.frame(predict(dummies,newdata = train_data))
Here we are creating and converting the variables into dummy variables. Let's see how the columns are names in the data frame df_ohe
colnames(df_ohe)
[1] "Course_Domain.Business" "Course_Domain.Development"
[3] "Course_Domain.Finance & Accounting" "Course_Domain.Software Marketing"
[5] "Course_Type.Course" "Course_Type.Degree"
[7] "Course_Type.Program"
So, all the variables in the two column were given a new name and each have the value 0 or 1..Awesome !!
df_train_ohe = cbind(train_data[,-c(which(colnames(train_data) %in% ohe))],df_ohe)
colnames(df_train_ohe)
The new list of columns in your training data set are below
colnames(df_train_ohe)
[1] "ID" "Day_No"
[3] "Course_ID" "Short_Promotion"
[5] "Public_Holiday" "Long_Promotion"
[7] "User_Traffic" "Competition_Metric"
[9] "Sales" "Course_Domain.Business"
[11] "Course_Domain.Development" "Course_Domain.Finance & Accounting"
[13] "Course_Domain.Software Marketing" "Course_Type.Course"
[15] "Course_Type.Degree" "Course_Type.Program"
You started with 11 variables, and now you have 16 columns, feed it in your XGB or Linear Regression..By the way, you still have 7 more days for the Hacathon..Try it 🙂
Keep Learning 🙂
The Data Monk
The Data Monk services
We are well known for our interview books and have 70+ e-book across Amazon and The Data Monk e-shop page . Following are best-seller combo packs and services that we are providing as of now
- YouTube channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel - Website – ~2000 completed solved Interview questions in SQL, Python, ML, and Case Study
Link – The Data Monk website - E-book shop – We have 70+ e-books available on our website and 3 bundles covering 2000+ solved interview questions. Do check it out
Link – The Data E-shop Page - Instagram Page – It covers only Most asked Questions and concepts (100+ posts). We have 100+ most asked interview topics explained in simple terms
Link – The Data Monk Instagram page - Mock Interviews/Career Guidance/Mentorship/Resume Making
Book a slot on Top Mate
The Data Monk e-books
We know that each domain requires a different type of preparation, so we have divided our books in the same way:
1. 2200 Interview Questions to become Full Stack Analytics Professional – 2200 Most Asked Interview Questions
2.Data Scientist and Machine Learning Engineer -> 23 e-books covering all the ML Algorithms Interview Questions
3. 30 Days Analytics Course – Most Asked Interview Questions from 30 crucial topics
You can check out all the other e-books on our e-shop page – Do not miss it
For any information related to courses or e-books, please send an email to nitinkamal132@gmail.com
Comments ( 2 )
can it be simplified more?
Nice explanation