Myntra Senior Business Analyst Questions
The Analytics domain is a very rapidly developing domain and there is an ever-growing job opportunity in this domain. We will keep everything short and simple.
Myntra Senior Business Analyst Questions
Target job roles – Business Analyst, Data Analyst, Data Scientist, Business Intelligence Engineer, Product Analyst, Machine Learning Engineer, Data Engineer
Target Companies – FAANG and only product-based companies
CTC offered –
12 to 20 LPA for Level 1 (0 to 4 YOE)
20 to 35 LPA for Level 2 (Senior level – 4 to 7 YOE )
35 to 50 LPA for Level 3 (Team Lead or Manager – 7 to 9 YOE)
50 to 80 LPA for Level 4 (Manager or Senior Manager – 9 to 12 YOE)
Tools and Technologies required
SQL – 9/10
Python – 7/10
Visualization tool (Power BI or Tableau) – Good to have
Machine Learning Algorithm – Expert in at least a couple of algorithms (if going for Data Science role)
Why The Data Monk?
We are a group of 30+ people with ~8 years of Analytics experience in product-based companies. We take interviews on a daily basis for our organization and we very well know what is asked in the interviews.
Other skill enhancer website charge 2lakh+ GST for courses ranging from 10 to 15 months.
We only focus on making you a clear interview with ease. We have released our Become a Full Stack Analytics Professional for anyone in 2nd year of graduation to 8-10 YOE. This book contains 23 topics and each topic is divided into 50/100/200/250 questions and answers. Pick the book and read it thrice, learn it, and appear in the interview.
We also have a complete Analytics interview package
– 2200 questions ebook (Rs.1999) + 23 ebook bundle for Data Science and Analyst role (Rs.1999)
– 4 one-hour mock interviews, every Saturday (top mate – Rs.1000 per interview)
– 4 career guidance sessions, 30 mins each on every Sunday (top mate – Rs.500 per session)
– Resume review and improvement (Top mate – Rs.500 per review)
Total cost – Rs.10500
Discounted price – Rs. 9000
How to avail of this offer?
Send a mail to nitinkamal132@gmail.com
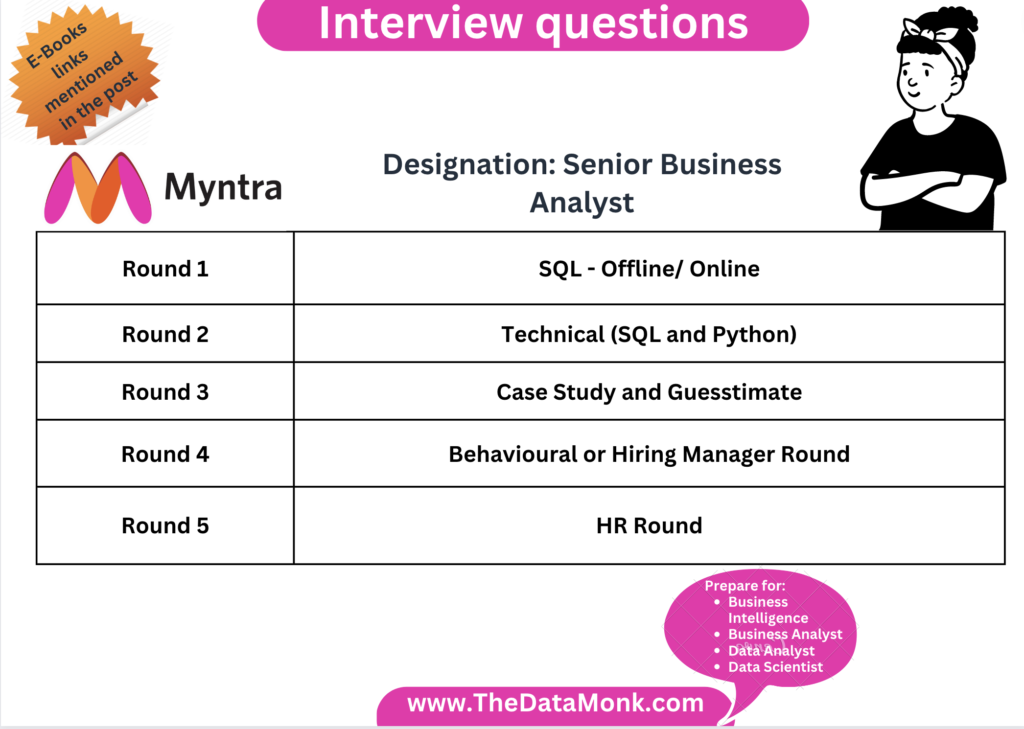
Myntra Senior Business Analyst Questions
Company – Myntra
Designation – Senior Business Analyst
Year of Experience required – 3 to 6 years
Technical expertise – SQL, Python, and Case Study
Salary offered – 20 to 30 LPA
Number of Rounds – In general there are 4 rounds + HR round. The first round could be offline test with 50 SQL questions or online test or one more round of SQL screening
Amazon Business Intelligence Engineer Interview Questions
Myntra SQL Interview Questions
In an EmployeeDetails table, we have 3 columns:-
Emp_id, Emp_Name, and Mgr_id
The Manager id is nothing but the employee id of some employee. Example
1, A, 2
2, B, 3
3, C, 4
B is the manager of A and C is the manager of B.
Output required
| Employee Name | Manager Name |
| A | B |
| B | C |
| C | D |
Write a code in SQL to get the desired output.
Ans
SELECT e1.emp_Id EmployeeId, e1.emp_name EmployeeName,
e1.emp_mgr_id ManagerId, e2.emp_name AS ManagerName
FROM tblEmployeeDetails e1
JOIN tblEmployeeDetails e2
ON e1.emp_mgr_id = e2.emp_id
Now in the above example, we have used Inner join as a part of the self join, the above will query will work fine for all the employees who have a Manager, but the Managing Director, CEO’s, etc. won’t necessarily have a Manager. What part of the query will you change to make sure all the employees of the company is present in the output.
Ans.
Instead of Inner Join, go for a left join. Thus, you will have all the employees name from this table and you can extract the name of
SELECT e1.emp_Id EmployeeId, e1.emp_name EmployeeName,
e1.emp_mgr_id ManagerId, e2.emp_name AS ManagerName
FROM tblEmployeeDetails e1
LEFT JOIN tblEmployeeDetails e2
ON e1.emp_mgr_id = e2.emp_id
What is a Cross-Join?
Cross join can be defined as a cartesian product of the two tables included in the join. The table after join contains the same number of rows as in the cross-product of the number of rows in the two tables.
SELECT stu.name, sub.subject
FROM students AS stu
CROSS JOIN subjects AS sub;
What is an Index?
A database index is a data structure that provides a quick lookup of data in a column or columns of a table. It enhances the speed of operations accessing data from a database table at the cost of additional writes and memory to maintain the index data structure.
How do the SQL commands flow at the back end?
Order of execution for an SQL query
1) FROM, including JOINs
2) WHERE
3) GROUP BY
4) HAVING
5) WINDOW Functions
6) SELECT
7) DISTINCT
8) UNION
9) ORDER BY
10) LIMIT AND OFFSET
Write a query to get all the student with name length 10, starting with K and ending with z.
select name
from student
where length(name)=10 and lower(name) like ‘k%z’
Write a SQL query to get the second highest query using Ranking
Note: Dense_rank() has been used to handle duplicate salaries if there are any.
With result as
{
select salary,
dense_rank() over (order by salary desc) as salaryrank
from employees
}
select top 1 salaryfrom result
where salaryrank = 2
Can you use HAVING command without any aggregate function in SQL?
No it’s not necessary for having to use aggregate functions and even without group by having can exist.
Eg: This query works well in PostgreSql
select 1 having 1 = 1;
What is the difference between COUNT(*) and COUNT(ColName)?
COUNT(*) : It will return total number of records in table.
COUNT(ColName) : It will return total number of records where value for that ColName is Not-Null.
Eg: Table A
ID, Name, Dept
1,’A’,’D1′
2,’B’,NULL
3,’C’,’D5′
COUNT(*) : 3
COUNT(Dept) : 2
COUNT(ID) : 3
What is indexing in SQL?
An index can be used to efficiently find all rows matching some column in your query and then walk through only that subset of the table to find exact matches. If you don’t have indexes on any column in the WHERE clause, the SQL server has to walk through the whole table and check every row to see if it matches, which may be a slow operation on big tables.
Creating an index involves the CREATE INDEX statement, which allows you to name the index,
to specify the table and which column or columns to index, and to indicate whether the index
is in an ascending or descending order.
Basic syntax
CREATE INDEX index_name ON table_name;
Single Column Index
CREATE INDEX index_name
ON table_name (column_name);
Unique Index
CREATE UNIQUE INDEX index_name
on table_name (column_name);
Myntra Case Study Interview Questions
The profit of a company selling mobile back cover is declining. List out all the possible reasons
Following is the way in which discussion proceeded with the interviewer:-
1. The demand itself has declined i.e. customers are not using cover that much. Asked to think more by the interviewer
2. Maybe the competitor is also facing loss which again means that the demand is low. Competitors are making a decent profit
3. Bad Marketing – The company is not putting stalls or shops in a crowded place. The interviewer told that the company was making a decent profit 6 months back
4. Maybe the footfall of the mall or place decreased. Could be(first positive response)
5. Maybe a popular mobile phone shop has shifted somewhere else. Could be(again a so-so response)
6. Maybe the other companies have reduced the price of their product which is why customers are drifting to these companies. The interviewer seemed pleased
7. New technology in the cover market to make covers more durable and the company we are talking about is using the same old technology. Seemed good enough point
8. Since we are talking about back covers, there could be new or trending designs which are not produced by the company
9. The company has not registered on different e-commerce websites and the website they are present on is not doing good business. He looked satisfied with the point
Myntra Big Data and Python Interview Questions
What is Hive Metastore?
Answer: Hive megastore is a database that stores metadata about your Hive tables (eg. Table name, column names and types, table location, storage handler being used, number of buckets in the table, sorting columns if any, partition columns if any, etc.).
When you create a table, this megastore gets updated with the information related to the new table which gets queried when you issue queries on that table.
Hive is a central repository of hive metadata. it has 2 parts of services and data. by default, it uses derby DB in local disk. it is referred to as embedded megastore configuration. It tends to the limitation that only one session can be served at any given point of time.
Can you explain the difference between batch processing and stream processing, and when would you use one over the other?
Batch processing involves processing data in large volumes and in batches, while stream processing involves processing data in real-time as it arrives. Batch processing is typically used when dealing with large volumes of data that can be processed in batches, such as nightly processing of transactional data or log files. Stream processing, on the other hand, is used when immediate action is required, such as in real-time analytics or fraud detection.
What is a distributed file system, and how does it differ from a traditional file system?
A distributed file system is a file system that is distributed across multiple machines in a network. It allows multiple users to access the same files and data from different locations simultaneously. Distributed file systems are designed to be fault-tolerant and scalable, which makes them ideal for handling large amounts of data.
In contrast, traditional file systems are stored on a single machine and can only be accessed by one user at a time. Traditional file systems are not designed to handle large amounts of data or to be fault-tolerant.
Different file formats to store and process input data using Apache Hadoop
CSV Files
CSV files are an ideal fit for exchanging data between hadoop and external systems. It is advisable not to use header and footer lines when using CSV files.
JSON Files
Every JSON File has its own record. JSON stores both data and schema together in a record and also enables complete schema evolution and splitability. However, JSON files do not support block-level compression.
Avro FIiles
This kind of file format is best suited for long term storage with Schema. Avro files store metadata with data and also let you specify independent schema for reading the files.
Parquet Files
A columnar file format that supports block level compression and is optimized for query performance as it allows selection of 10 or less columns from from 50+ columns records.
We have also collated all these real interview questions from 50+ companies in our book 2200+ Most Asked Analytics interview Questions(with Answers)
The Data Monk services
We are well known for our interview books and have 70+ e-book across Amazon and The Data Monk e-shop page . Following are best-seller combo packs and services that we are providing as of now
- YouTube channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel - Website – ~2000 completed solved Interview questions in SQL, Python, ML, and Case Study
Link – The Data Monk website - E-book shop – We have 70+ e-books available on our website and 3 bundles covering 2000+ solved interview questions. Do check it out
Link – The Data E-shop Page - Instagram Page – It covers only Most asked Questions and concepts (100+ posts). We have 100+ most asked interview topics explained in simple terms
Link – The Data Monk Instagram page - Mock Interviews/Career Guidance/Mentorship/Resume Making
Book a slot on Top Mate
The Data Monk e-books
We know that each domain requires a different type of preparation, so we have divided our books in the same way:
1. 2200 Interview Questions to become Full Stack Analytics Professional – 2200 Most Asked Interview Questions
2.Data Scientist and Machine Learning Engineer -> 23 e-books covering all the ML Algorithms Interview Questions
3. 30 Days Analytics Course – Most Asked Interview Questions from 30 crucial topics
You can check out all the other e-books on our e-shop page – Do not miss it
For any information related to courses or e-books, please send an email to nitinkamal132@gmail.com