Supervised Learning Interview Question. This is the 2nd part of the series Supervised Learning Interview Question
Part 1-https://thedatamonk.com/supervised-learning-interview-questions/
Part 3- https://thedatamonk.com/supervised-learning-data-science-questions/
Part 4-https://thedatamonk.com/supervised-learning-questions/
1. Let’s create our dataset first. We will create Thyroid data set with attributes as Weight, Blood Sugar, and Sex(M=1,F=0)
#Weight,Blood Sugar, and gender Male = 1, Female = 0
X = [[80, 150,0], [90, 200, 0], [95, 160, 1], [110, 200, 1], [70, 110, 0],
[60,100,1], [70, 300, 0],
[100,200,1], [140, 300, 0], [60, 100, 1], [70,100,0], [100,300,1], [70, 110, 1]]
y = [‘Thyroid’,’Thyroid’,’Normal’,’Normal’,’Normal’,’Normal’,’Thyroid’,’Normal’,’Thyroid’,
‘Normal’,’Normal’,’Thyroid’,’Normal’]
2. What are X and y?
The list X contains the attributes and y contains the classification
3. How to build the testing dataset?
We have to create a test data set also. Let’s take some values which are not identical to the above values but are close to the labels. So we know that [90,200,0] is a thyroid patient , so we will test our model on [100,250,0] and we have already labeled it to Thyroid
X_test = [[100,250,0],[70,110,1],[60,100,0],[120,300,1]]
y_test = [‘Thyroid’,’Normal’,’Normal’,’Thyroid’]
4. Let’s understand Decision Tree first. Define Decision Tree.
Decision trees learn from data to approximate a sine curve with a set of if-then-else decision rules. The deeper the tree, the more complex the decision rules and the fitter the model. Decision tree builds classification or regression models in the form of a tree structure. It breaks down a data set into smaller and smaller subsets while at the same time an associated decision tree is incrementally developed. The final result is a tree with decision nodes and leaf nodes.
5. Define Leaf and Node of a Decision Tree
A decision node has two or more branches. Leaf node represents a classification or decision. The topmost decision node in a tree which corresponds to the best predictor called root node. Decision trees can handle both categorical and numerical data.
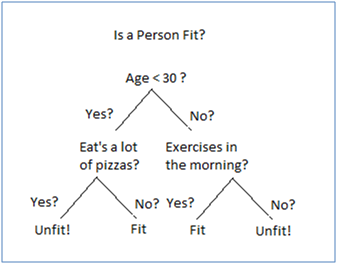
6. How does a Decision Tree works? What is splitting?
Decision tree follows three steps – Splitting, Pruning, and Tree Selection.
Decision Tree starts with Splitting which is a process of partitioning the data into subsets. Splits are formed on a particular variable. In the above Decision tree the split on the first level happened on the variable which is Age. Then further split happened on Pizza and exercise in morning.
7. What is pruning?
The shortening of branches of the tree. Pruning is the process of reducing the size of the tree by turning some branch nodes into leaf nodes, and removing the leaf nodes under the original branch. Pruning is useful because classification trees may fit the training data well, but may do a poor job of classifying new values. A simpler tree often avoids over-fitting
8. What is tree selection?
The process of finding the smallest tree that fits the data. Usually this is the tree that yields the lowest cross-validated error.
9. What is entropy?
A decision tree is built top-down from a root node and involves partitioning the data into subsets that contain instances with similar values (homogeneous). If the sample is completely homogeneous the entropy is zero and if the sample is an equally divided it has entropy of one.
10. Let’s create a Decision Tree Classifier
from sklearn import tree
DecisionT = tree.DecisionTreeClassifier()
DecisionT = DecisionT.fit(X,y)
DecisionT_prediction = DecisionT.predict(X_test)
print (DecisionT_prediction)
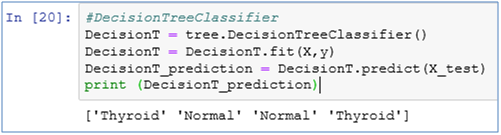
11. Explain the above code
First we imported tree package from sklearn library. The function DecisionTreeClassifier in the tree package holds the model so we initialize our model ‘DecisionT’ with the above function. This will create a decision tree model. Now we need to fit the model on our training data set i.e. X and y. So we have used DecisionT.fit(X,y).
Predict function takes up your test data set and predicts it on the basis of values
12. What is a Random forest?
Random forests is a supervised learning algorithm. It can be used both for classification and regression. It is also the most flexible and easy to use algorithm. A forest is comprised of trees. It is said that the more trees it has, the more robust a forest is. Random forests creates decision trees on randomly selected data samples, gets prediction from each tree and selects the best solution by means of voting. It also provides a pretty good indicator of the feature importance.
13. What are the applications of Random Forest?
Random forests has a variety of applications, such as recommendation engines, image classification and feature selection. It can be used to classify loyal loan applicants, identify fraudulent activity and predict diseases. It lies at the base of the Boruta algorithm, which selects important features in a dataset.
Supervised Learning Interview Question
14. What is feature importance in Random Forest?
A great quality of the random forest algorithm is that it is very easy to measure the relative importance of each feature on the prediction. Sklearn provides a great tool for this, that measures a features importance by looking at how much the tree nodes, which use that feature, reduce impurity across all trees in the forest. It computes this score automatically for each feature after training and scales the results, so that the sum of all importance is equal to 1.
15. How does the Random Forest Algorithm works?
Step 1 – The algorithm will select a random sample from the given dataset
Step 2 – Construct a complete Decision Tree and get a prediction result
Step 3 – Get a vote from each predicted result
Step 4 -Select the prediction result with the most votes as the final prediction.
16. What are the advantages of Random Forest?
The one main advantage of Random Forest is that it considers almost all the combination of results so the accuracy on the training dataset is very high. It does not suffer from over fitting problem.
One more advantage is that it can be used in Regression and Classification problem
17. What are the disadvantages of Random Forest?
It fails to provide the same level of accuracy on the test data set because the algorithm is not trained on unseen values, so it loses accuracy there.
The model is made up of multiple trees, so it is hard to interpret the backend algorithm
18. Do a Random Forest vs Decision Tree.
Many decision trees make up a forest
Decision trees are computationally faster
Random Forest is difficult to interpret
19. We already have a Decision Tree model at place, now let’s create a Random Forest Classifier?
from sklearn.ensemble import RandomForestClassifier
RandomF = RandomForestClassifier()
RandomF.fit(X,y)
RandomF_prediction = RandomF.predict(X_test)
print (RandomF_prediction)
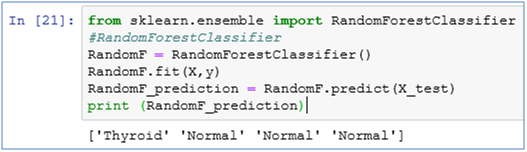
20. Explain the code above.
The process of building the model is same as Decision Tree. Import the Random Forest Classifier package, fit the model on the training dataset, use predict() function to predict values for test data

Try to solve these questions, other members will evaluate your answer and provide sufficient support.
inMobi- https://thedatamonk.com/inmobi-data-science-interview-question/
HSBC– https://thedatamonk.com/hsbc-business-analyst-interview-questions/
OLA– https://thedatamonk.com/ola-data-analyst-interview/
Big Basket- https://thedatamonk.com/big-basket-data-analyst-interview-questions/
Swiggy – https://thedatamonk.com/swiggy-data-analyst-interview-questions/
Accenture – https://thedatamonk.com/accenture-business-analyst-interview-question/
Deloitte – https://thedatamonk.com/deloitte-data-scientist-interview-questions/
Amazon – https://thedatamonk.com/amazon-data-science-interview-questions/
Myntra – https://thedatamonk.com/myntra-data-science-interview-questions-2/
Flipkart – https://thedatamonk.com/flipkart-business-analyst-interview-questions/
SAP – https://thedatamonk.com/sap-data-science-interview-questions/
BOX8 – https://thedatamonk.com/box8-data-analyst-interview-questions-2/
Zomato – https://thedatamonk.com/zomato-data-science-interview-questions/
Oracle – https://thedatamonk.com/oracle-data-analyst-interview-questions/
Let’s create one more model, a basic but highly effective model i.e. Logistic Regression model
Keep Learning 🙂
XtraMous