We know that each domain requires a different type of preparation, so we have divided our books in the same way:
Our best seller:
✅Become a Full Stack Analytics Professional with The Data Monk’s master e-book with 2200+ interview questions covering 23 topics – 2200 Most Asked Interview Questions
Machine Learning e-book
✅Data Scientist and Machine Learning Engineer ->23 e-books covering all the ML Algorithms Interview Questions
Domain wise interview e-books
✅Data Analyst and Product Analyst Interview Preparation ->1100+ Most Asked Interview Questions
✅Business Analyst Interview Preparation ->1250+ Most Asked Interview Questions
The Data Monk – 30 Days Mentorship program
We are a group of 30+ people with ~8 years of Analytics experience in product-based companies. We take interviews on a daily basis for our organization and we very well know what is asked in the interviews.
Other skill enhancer websites charge 2lakh+ GST for courses ranging from 10 to 15 months.
We only focus on making you a clear interview with ease. We have released our Become a Full Stack Analytics Professional for anyone in 2nd year of graduation to 8-10 YOE. This book contains 23 topics and each topic is divided into 50/100/200/250 questions and answers. Pick the book and read it thrice, learn it, and appear in the interview.
We also have a complete Analytics interview package
– 2200 questions ebook (Rs.1999) + 23 ebook bundle for Data Science and Analyst role (Rs.1999)
– 4 one-hour mock interviews, every Saturday (top mate – Rs.1000 per interview)
– 4 career guidance sessions, 30 mins each on every Sunday (top mate – Rs.500 per session)
– Resume review and improvement (Top mate – Rs.500 per review)
YouTube channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel
CRED Data Science Interview
Company: CRED
Designation: Data Scientist
Year of Experience Required: 0 to 4 years
Technical Expertise: SQL, Python/R, Statistics, Machine Learning, Case Studies
Salary Range: 12LPA – 30LPA
CRED is a members-only platform that rewards individuals for timely credit card bill payments. Founded to simplify credit card management and improve financial health, CRED offers exclusive rewards and premium experiences to users with high credit scores. If you’re preparing for a Data Science role at CRED, here’s a detailed breakdown of their interview process and the types of questions you can expect.

Difficulty of Questions
SQL – 9/10
1) How can you find the second highest salary from an employees table?
SELECT DISTINCT salary
FROM employees
ORDER BY salary DESC
LIMIT 1 OFFSET 1;2) How do you retrieve employees earning more than the average salary?
SELECT name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);3) How can you find the highest-paid employee in each department?
SELECT e.name, e.salary, e.department_id
FROM employees e
WHERE e.salary = (
SELECT MAX(salary)
FROM employees
WHERE department_id = e.department_id
);4) How do you count the number of employees in each department?
SELECT department_id, COUNT(*) AS total_employees
FROM employees
GROUP BY department_id;5) How can you find duplicate records based on the email column?
SELECT email, COUNT() AS count
FROM employees
GROUP BY email
HAVING COUNT() > 1;R/Python – 7/10
1) Write a Python function that takes a list of numbers as input and returns a new list where each element is doubled, using the map() function and a lambda function.

2) Write a Python function that takes a list of numbers as input and returns a new list containing only the even numbers, using the filter() function and a lambda function.

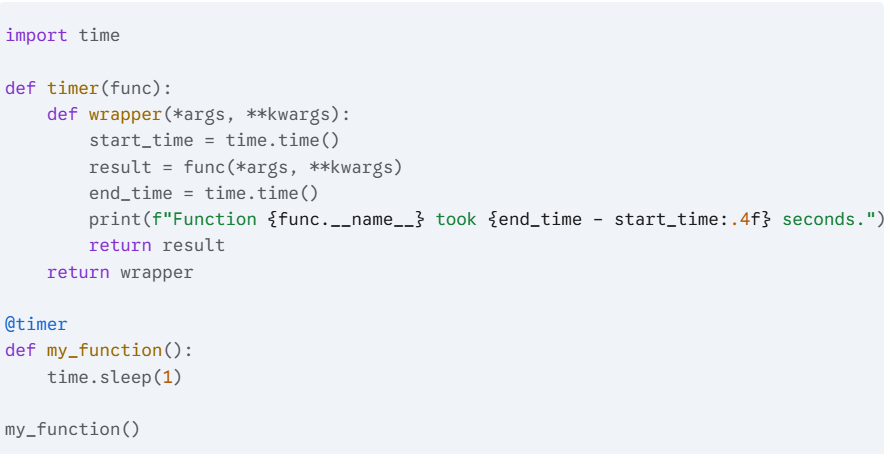
3) Write a Python decorator that measures and prints the execution time of a function.
4) Given two sets, set1 and set2, write Python code to find the elements that are present in set1 but not in set2.

5) Create a Python class called Circle with an attribute radius and a method area() that calculates and returns the area of the circle.

Statistics/ML
1) What is an independent variable and what if I have three independent variables in my model and no dependent variable?
An independent variable is a variable that influences the dependent variable but is not affected by it.
If you have three independent variables but no dependent variable, then:
- There is no clear relationship to model.
- The dataset may be unsupervised, where clustering or pattern detection techniques (e.g., K-Means, PCA) might be used.
- If regression is intended, a dependent variable is required to establish relationships.
2) What are the steps you will take to improve the performance of a poor-performing query?
To optimize a slow SQL query, follow these steps:
- Check Indexes: Ensure appropriate indexes exist on filtering columns.
- Analyze Execution Plan: Use EXPLAIN to identify bottlenecks.
- Optimize Joins: Avoid unnecessary joins and use proper join types.
- Use WHERE Instead of HAVING: Filter data earlier in the query.
- Limit Data Scanned: Use SELECT specific columns instead of SELECT *.
- Partition Large Tables: Helps improve query speed for large datasets.
- Avoid Subqueries: Use JOINs or CTEs instead of nested queries.
3) What is the relationship between sample size and margin of error? What do they represent?
- Sample size refers to the number of observations in a dataset.
- Margin of error quantifies the uncertainty in an estimate.
Relationship:
- Larger sample size → Smaller margin of error (more accurate estimate).
- Smaller sample size → Larger margin of error (less confidence in results).
For example, in survey polling, increasing respondents reduces uncertainty in predictions.
4) What methods are used for Missing Value Treatments? Are there any disadvantages of using them in your dataset?
Techniques:
- Mean/Median/Mode Imputation (for numerical data).
- Forward/Backward Fill (for time-series data).
- KNN Imputation (uses similar records to estimate missing values).
- Dropping Missing Data (if missing values are <5%).
Disadvantages:
- Imputation can introduce bias.
- Forward fill assumes data follows a pattern, which may not be true.
- KNN imputation can be computationally expensive for large datasets.
5) Given a random Bernoulli trial generator, how do you return a value sampled from a normal distribution?
Answer:
Use the Central Limit Theorem (CLT):
- Generate multiple Bernoulli trials (0 or 1 outcomes).
- Sum a large number of these trials.
- Apply mean and variance transformations to approximate a normal distribution.
- Alternatively, use Box-Muller Transform or Inverse Transform Sampling.
Case Study
Problem Statement:
CRED wants to build a predictive model to identify users who are likely to default on their credit card bill payments. As a data scientist, your task is to analyze user transaction patterns, identify key risk factors, and recommend strategies to reduce defaults.
Dataset Overview:
You have access to a dataset containing past user transactions and credit history. The dataset includes the following attributes:
- User_ID – Unique identifier for each user
- Credit_Score – User’s credit score (300–900)
- Total_Credit_Limit – Maximum credit available to the user
- Current_Outstanding_Amount – Amount currently due on the user’s credit card
- Last_Payment_Amount – Amount paid in the last billing cycle
- Last_Payment_Date – Date when the last payment was made
- Missed_Payments_Last_6M – Number of missed payments in the last 6 months
- Average_Monthly_Spending – User’s average monthly credit card spending
- Cash_Advance_Usage – Amount of cash withdrawals using a credit card
- Interest_Charged_Last_6M – Total interest paid by the user in the last 6 months
- Default_Flag – Whether the user defaulted on payment (1 = Yes, 0 = No)
Key Questions to Answer:
1. What are the key factors influencing credit card payment defaults?
- Does a lower credit score indicate a higher risk of default?
- How does a user’s spending pattern impact their ability to pay bills?
- Are users with frequent missed payments more likely to default?
2. How can we predict defaults more accurately?
- Should we build a model using historical payment behavior?
- Can real-time spending patterns help predict potential defaulters?
- How can we use user segmentation to categorize risk levels?
3. What proactive strategies can CRED implement to reduce defaults?
- Should high-risk users receive frequent payment reminders?
- Can CRED introduce financial planning tools to encourage timely payments?
- How can rewards and incentives be optimized to promote on-time payments?
Key Insights & Business Recommendations
1. Identifying High-Risk Users
- Credit Score Analysis: Users with a credit score below 650 have a significantly higher probability of defaulting.
- Missed Payment Patterns: Users who missed more than two payments in the last six months are at a high risk of default.
- Spending vs. Payment Behavior: Users with high monthly spending but low payment amounts are more likely to default.
2. Improving Default Prediction Models
- Machine Learning for Risk Scoring: Implementing an AI-driven risk assessment model based on past payment history, spending habits, and outstanding balances.
- Real-Time Monitoring: Tracking sudden spikes in spending or cash advance usage to flag potential risk early.
- Segmentation-Based Prediction: Categorizing users into low, medium, and high-risk groups based on transaction and repayment behavior.
3. Reducing Defaults Through Proactive Interventions
- Personalized Payment Reminders: Sending customized payment reminders based on a user’s past behavior (e.g., more frequent reminders for high-risk users).
- Interest Reduction for Timely Payments: Offering reduced interest rates for users who consistently pay their bills on time to encourage good credit habits.
- Rewards for Consistent On-Time Payments: Introducing higher cashback or exclusive rewards for users who make full and timely payments each month.
4. Enhancing User Engagement and Financial Wellness
- Spending Insights & Alerts: Providing users with insights on their spending habits and warning them if they are at risk of missing payments.
- Credit Limit Adjustments: Suggesting appropriate credit limits to prevent over-borrowing and defaults.
- Financial Education & Advisory: Offering AI-driven financial coaching to educate users on better money management and debt reduction strategies.
Basic, you can practice a lot of case studies and other statistics topics here –
http://thedatamonk.com/data-science-resources/