here comes the boring part, but this is what Data Science is. Give it a shot, because there is no point in becoming a Data Scientist without knowing how to calculate IQR or in fact what is IQR?
Statistics is a set of concepts, rules and procedures which help us in the study of data. Basically, statistics help us to describe properties of a data and draw conclusions about the whole population.
Statistics may be defined as a science of collection, presentation, analysis and presentation of data.
Statistics help us in the following 3 ways:-
1. Organize the whole data in the form of various graphs, charts, tables, etc.
2. Analyze the data and understand statistical techniques underlying decisions that affect our lives.
3. Interpret the data and make informed decisions
In a nutshell, Statistics is a collection of methods for collecting, displaying, analyzing, and drawing conclusions from data.
This was stats for you, now we know that it is something which help you extract juice from the data. Time to dive in the basic terminology, so that you don’t feel awkward talking to a data science who will use these terms regularly.
What are the basic terminologies in statistics for data science?
Before starting with the terminologies, let’s take an example which should help you understand the terms.
“India is a country with over 1 billion people. It’s one of the largest countries in the World. People use vehicles to go from one place to another. I wish to know the value of all the four wheelers in India. It’s really impractical to solve this problem by computing the value of each and every vehicle and taking the average.
Instead, the best we can do would be to estimate the average. One natural way to do so would be to randomly select some of the four wheelers, say 1000 of them, ascertain the value of each of those cars, and find the average of those 1000 numbers. The set of all those millions of vehicles is called thepopulation of interest, and the number attached to each one, its value, is a measurement. The average value is a parameter: a number that describes a characteristic of the population, in this case monetary worth. The set of 200 cars selected from the population is called a sample, and the 200 numbers, the monetary values of the cars we selected, are the sample data. The average of the data is called a statistic: a number calculated from the sample data. This example illustrates the meaning of the following definitions.
1. Population –Population is the complete targeted group of people/objects on which the analysis needs to be performed. If the target is Mumbai population then the population will be the total number of people living in Mumbai.
2. Sample –A sample is like a subset of the population. Most of the times you won’t be able to do your complete analysis on the Population data set as there will be hundreds of millions of rows and processing it will consume a lot of time. So, we take a sample of data which should be random and unbiasedfrom the population.
3. Measurement –A measurement is a number or attributes computed for each member of a population or of a sample. If you want to know the income of each citizen of India. Then the complete 1.25 Billion is your population, 1 or 2 Million will be your sample and the income of each citizen is your measurement.
4. Sample data –The sample extracted from the population along with the measurement is called Sample data
5. Data points –Data point refers to individual instances of data. A heap of data points create a data. Remember that when we talk of “data,” what we mean is a set of aggregated data points.
6. Data Set –A “data set” is a well-structured set of data points. Let us define a data set as a collection of data points that has been observed on similar objects and formatted in similar ways. Thus, a compilation of the written names and the written ages of a room full of people is a data set.
7. Data Types –Data points can be of several “data types,” such as numbers, or text, or date-times.
For example, addition is an operation we can compute on integer data types (2+2=4), but not on text data types (“two”+”two”=???). Concatenation is an operation we can compute on text.
There are 4 data types in statistics. These are:-
a. Nominal – Nominal data are recorded as categories. For this reason, nominal data is also known as categorical data. For example, rocks can be generally categorized as igneous, sedimentary and metamorphic.
b. Numerical – These data have meaning as a measurement, such as a person’s height, weight, IQ, or blood pressure; or they’re a count, such as the number of stock shares a person owns, how many teeth a dog has, or how many pages you can read of your favorite book before you fall asleep. (Statisticians also call numerical data quantitative data.)
c. Ratio – Ratio data are recorded on an interval scale with a true zero point. Mass, length, time, plane angle, energy and electric charge are examples of physical measures that are ratio scales. Informally, the distinguishing feature of a ratio scale is the possession of a zero value. For example, the Kelvin temperature scale has a non-arbitrary zero point of absolute zero.
d. Interval – Interval data are recorded not just about the order of the data points, but also the size of the intervals in between data points. A highly familiar example of interval scale measurement is temperature with the Celsius scale. In this particular scale, the unit of measurement is 1/100 of the temperature difference between the freezing and boiling points of water. The zero point, however is arbitrary.
8. Variables –A variable is not only something that we measure, but also something that we can manipulate and control.
It is a property of an object or event that can take on different values. For example, college major is a variable that takes on values like mathematics, computer science, English, psychology, etc.

There are 2 types of statistics i.e. Descriptive and Inferential Statistics.
9. Descriptive Statistics – Descriptive statistics is the branch of statistics that involves organizing, displaying, and describing data.
10. Inferential Statistics –Inferential statistics is the branch of statistics that involves drawing conclusions about a population based on information contained in a sample taken from that population.
2. Measurement in Statistics
We know that there are multiple ways in which you can analyze data and numbers. In this chapter we will deal with different ways in which you can deal with the clean data to get an overview of the numbers.
In simple words, suppose you have data of all the bikes in India. So, we will provide you basic measurement concepts which will help you know the data better.
Measurement is divided into 3 parts:-
1. Measures of Center –Mean, Median and Mode
2. Measure of Spread –Variance, Standard Deviation, Range and Inter-Quartile Range
3. Measures of Shape –Symmetric, Skewness, Kurtosis
Measures of Center
Plotting data in a frequency distribution shows the general shape of the distribution and gives a general sense of how the numbers are bunched. Several statistics can be used to represent the “center” of the distribution. These statistics are commonly referred to as measures of central tendency.
We generally use Mean, Median and Mode to see the center value of the population. You might be familiar with these topics but do spare some time to brush the concepts.
Mean
“The mean is the most common measure of central tendency and the one that can be mathematically manipulated. It is defined as the average of a distribution is equal to the SX / N. Simply, the mean is computed by summing all the scores in the distribution (SX) and dividing that sum by the total number of scores (N). ”
Example:
Heights of five people: 5 feet 6 inches, 5 feet 7 inches, 5 feet 10 inches, 5 feet 8 inches, 5 feet 8 inches.
The sum is: 339 inches.
Divide 339 by 5 people = 67.8 inches or 5 feet 7.8 inches.
The mean (average) is 5 feet 7.8 inches.
Median
“The median is the score that divides the distribution into halves; half of the scores are above the median and half are below it when the data are arranged in numerical order. The median is also referred to as the score at the 50th percentile in the distribution. The median location of N numbers can be found by the formula (N + 1) / 2. When N is an odd number, the formula yields a integer that represents the value in a numerically ordered distribution corresponding to the median location. ”
Examples:
Odd amount of numbers: Find the median of 5 feet 6 inches, 5 feet 7 inches, 5 feet 10 inches, 5 feet 8 inches, 5 feet 8 inches.
Line up your numbers from smallest to largest: 5 feet 6 inches, 5 feet 7 inches, 5 feet 8 inches, 5 feet 8 inches, 5 feet 10 inches.
The median is: 5 feet 8 inches (the number in the middle).
Even amount of numbers: Find the median of 7, 2, 43, 16, 11, 5
Line up your numbers in order: 2, 5, 7, 11, 16, 43
Add the 2 middle numbers and divide by 2: 7 + 11 = 18 ÷ 2 = 9
The median is 9.
Mode
“The mode of a distribution is simply
defined as the most frequent or common score in the distribution. The
mode is the point or value of X that corresponds to the highest point
on the distribution. If the highest frequency is shared by more than one
value, the distribution is said to be multimodal.
It is not uncommon to see distributions that are bimodal reflecting peaks in
scoring at two different points in the distribution.”
The most common result (the most frequent value) of a test, survey, or
experiment.
Example: Height Chart with people lined up in order of height, short to tall.
Find the mode of 5 feet 6 inches, 5 feet 7 inches, 5 feet 10 inches, 5 feet 8
inches, 5 feet 8 inches.
Put the numbers is order to make it easier to visualize: 5 feet 6 inches, 5
feet 7 inches, 5 feet 8 inches, 5 feet 8 inches, 5 feet 10 inches.
The mode is 5 feet 8 inches (it occurs the most, at 2 times).
Measure of Spread
Average values are good to know, but they don’t tell you
how the values are clustered. Measures of variability provide information about
the degree to which individual scores are clustered about or deviate from the
average value in a distribution.
Range
“The simplest measure of variability to
compute and understand is the range. The range is the difference between
the highest and lowest score in a distribution. Although it is easy to
compute, it is not often used as the sole measure of variability due to its
instability. Because it is based solely on the most extreme scores in the
distribution and does not fully reflect the pattern of variation within a
distribution, the range is a very limited measure of variability.”
Example: In {4, 6, 9, 3, 7} the lowest value is
3, and the highest is 9.
Interquartile Range (IQR) –
The interquartile range is a measure of where the “middle fifty” is in a data
set. Where a range is a measure of where the beginning and end are in a set, an
interquartile range is a measure of where the bulk of the values lie. That’s
why it’s preferred over many other measures of spread (i.e. the average or
median) when reporting things like school performance or SAT scores.
How to calculate IQR
Step 1: Put the numbers in order.
1, 2, 5, 6, 7, 9, 12, 15, 18, 19, 27.
Step 2: Find the median.
1, 2, 5, 6, 7, 9, 12, 15, 18, 19, 27.
Step 3: Place parentheses around the numbers above and
below the median.
Not necessary statistically, but it makes Q1 and Q3 easier to spot.
(1, 2, 5, 6, 7), 9, (12, 15, 18, 19, 27).
Step 4: Find Q1 and Q3
Think of Q1 as a median in the lower half of the data and think of Q3 as a
median for the upper half of data.
(1, 2, 5, 6, 7), 9, ( 12, 15, 18, 19,
27). Q1 = 5 and Q3 = 18.
Step 5: Subtract Q1 from Q3 to find the interquartile
range.
18 – 5 = 13.
Variance
Variance is the expectation of the squared deviation of a random variable from its mean, and it informally measures how far a set of (random) numbers are spread out from their mean.
Standard Deviation
The standard deviation (SD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values.
It is also defined as the positive square root of the variance. The variance is a measure in squared units and has little meaning with respect to the data. Thus, the standard deviation is a measure of variability expressed in the same units as the data. The standard deviation is very much like a mean or an “average” of these deviations
Standard deviation tells you how different and varied your data set really is. It shows you how far your numbers spread out from the mean and median.
The below example will help you with the steps to get variance and standard deviation
You survey households in your area to find the average rent they are paying. Find the standard deviation from the following data:
$1550, $1700, $900, $850, $1000, $950.
Step 1: Find the mean:
($1550 + $1700 + $900 + $850 + $1000 + $950)/6 = $1158.33
Step 2: Subtract the mean from each value.
This gives you the differences:
$1550 – $1158.33 = $391.67
$1700 – $1158.33 = $541.67
$900 – $1158.33 = -$258.33
$850 – $1158.33 = -$308.33
$1000 – $1158.33 = $158.33
$950 – $1158.33 = $208.33
Step 3: Square the differences you found in
Step 3:
$391.672 = 153405.3889
$541.672 = 293406.3889
-$258.332 = 66734.3889
-$308.332 = 95067.3889
$158.332 = 25068.3889
$208.332 = 43401.3889
Step 4: Add up all of the squares you found
in Step 3 and divide by 5 (which is 6 – 1):
(153405.3889 + 293406.3889 + 66734.3889 + 95067.3889 + 25068.3889 + 43401.3889)
/ 5 = 135416.66668
Step 5: Find the square root of the number
you found in Step 4 (the variance):
√135416.66668 = 367.99
The standard deviation is 367.99.
Measure of Shape
For
distributions summarizing data from continuous measurement scales, shape of
graph can be used to describe how the distribution rises and drops.
Symmetric – Distributions that have the same shape on both sides of
the center are called symmetric. A
symmetric distribution with only one peak is referred to as a normal
distribution.
Skewness – Skewness is a measure of the asymmetry
of the probability distribution of a real-valued random variable about its
mean. The skewness value can be positive or negative, or even undefined. The
qualitative interpretation of the skew is complicated and unintuitive.
Positively skewed – A distribution is positively skewed when is has a tail extending out to the right (larger numbers) When a distribution is positively skewed, the mean is greater than the median reflecting the fact that the mean is sensitive to each score in the distribution and is subject to large shifts when the sample is small and contains extreme scores.
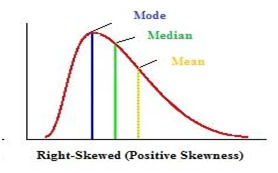
Negatively skewed – A negatively skwed distribution has an extended tail pointing to the left (smaller numbers) and reflects bunching of numbers in the upper part of the distribution with fewer scores at the lower end of the measurement scale.
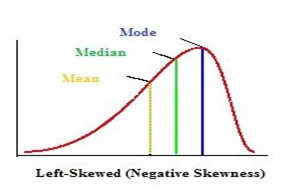
The formula to find skewness manually is this:
skewness = (3 * (mean – median)) / standard deviation
In order to use this formula, we need to know the mean and median, of course.
Skewness can be shown with a list of numbers as well as on a graph. For example, take the numbers 1,2, and 3. They are evenly spaced, with 2 as the mean (1 + 2 + 3 / 3 = 6 / 3 = 2). If you add a number to the far left (think in terms of adding a value to the number line), the distribution becomes left skewed:
-10, 1, 2, 3
Similarly, if you add a value to the far right, the set of numbers becomes right skewed:
1, 2, 3, 10
Kurtosis
Kurtosis is a measure of the combined sizes of the two tails. It measures the
amount of probability in the tails. The value is often compared to the kurtosis
of the normal distribution, which is equal to 3.
Most
important Analytical tests
There are many analytical tests which help you to
understand the relation between your data.
Here we will target to get through the following 4
concepts:-
1. Correlation
2. Regression
3. T-Test
4. Chi Square Test
Correlation
Correlation is one of the most basic and important
concept in data science. In a layman language, it is used to get the degree of
relationship between 2 variables.
For example – Height and Weight are related i.e. taller people are generally
heavier than shorter one. But, the correlation between these might not be
perfect.
Consider the variables family income and family expenditure. It is well known
that income and expenditure increase or decrease together. Thus they are
related in the sense that change in any one variable is accompanied by change in
the other variable.
Correlation can tell you something about the relationship between variables. It is used to understand:
1. Whether the relationship is positive or negative
2. Strength of relationship.
Correlation is a powerful tool that provides these vital pieces of information.
In the case of family income and family expenditure, it is easy to see that
they both rise or fall together in the same direction. This is called positive
correlation.
It is measured by what is called coefficient of correlation (r). Its numerical
value ranges from +1.0 to -1.0. It gives us an indication of the strength of
relationship.In general, r > 0 indicates positive relationship, r < 0
indicates negative relationship while r = 0 indicates no relationship (or that
the variables are independent and not related). Here r = +1.0 describes a
perfect positive correlation and r = -1.0 describes a perfect negative
correlation.
Closer the coefficients are to +1.0 and -1.0, greater is the strength of the relationship between the variables.
As a rule of thumb, the following guidelines on strength of relationship are often useful (though many experts would somewhat disagree on the choice of boundaries).
Value of r Strength of relationship
-1.0 to -0.5 or 1.0 to 0.5 Strong
-0.5 to -0.3 or 0.3 to 0.5 Moderate
-0.3 to -0.1 or 0.1 to 0.3 Weak
-0.1 to 0.1 None or very weak
Correlation is only appropriate for examining the
relationship between meaningful quantifiable data (e.g. air pressure,
temperature) rather than categorical data such as gender, favorite color etc.
Regression
There are two types of regression analysis:-
1. Linear Regression Analysis
2. Multiple Regression Analysis
Starting with Linear Regression Analysis, It is basically a technique used to
determine/predict the unknown value of a variable by looking at the known
values. If X and Y are two variables which are related, then linear regression
helps you to predict the value of Y.
A simple example can be the relationship between age of a person and his
maturity level. So we can say that these 2 are related and we can guess the
maturity level of the person.
By linear regression, we mean models with just one independent and one
dependent variable. The variable whose value is to be predicted is known as the
dependent variable and the one whose known value is used for prediction is
known as the independent variable.
Y
= a + bX
This is the linear regression of Y on X where a and b are unknown constant and
slope of the equation.
Choice of linear regression is one of the most important part of applying it.
For example, suppose you want to have 2 variables crop yield (Y) and rainfall
(X). Here construction of regression line of Y on X would make sense and would
be able to demonstrate the dependence of crop yield on rainfall. We would then
be able to estimate crop yield given rainfall.
Careless use of linear regression analysis could mean construction of
regression line of X on Y which would demonstrate the laughable scenario that
rainfall is dependent on crop yield; this would suggest that if you grow really
big crops you will be guaranteed a heavy rainfall.
If the regression coefficient of Y on X is 0.53 units, it would indicate that Y
will increase by 0.53 if X increased by 1 unit. A similar interpretation can be
given for the regression coefficient of X on Y.
Multiple Linear Regression
As the name suggests, multiple linear regression uses 2
or more variables as a predictor to get the value of the unknown variable.
For example the yield of rice per acre depends upon quality of seed, fertility
of soil, fertilizer used, temperature, rainfall. If one is interested to study
the joint affect of all these variables on rice yield, one can use this
technique.
An additional advantage of this technique is it also
enables us to study the individual influence of these variables on yield.
Y = b0 + b1 X1 + b2 X2 + …………………… + bk Xk
Here b0 is the intercept and b1,b2,b3, etc. are analogous
to the slope in the linear regression.
You need to know whether your regression is good or not. In order to judge your
regression model examine the coefficient of determination(R2) which always lies
between 0 and 1. The closer the value of R2 to 1, the better is the model.
A related question is whether the independent variables individually influence
the dependent variable significantly. Statistically, it is equivalent to
testing the null hypothesis that the relevant regression coefficient is zero.
This can be done using t-test. If the t-test of a
regression coefficient is significant, it indicates that the variable is in
question influences Y significantly while controlling for other independent
explanatory variables.
Difference between linear regression and multiple
regression?
In simple linear regression a single independent variable is used to predict
the value of a dependent variable. In multiple linear regression two or more
independent variables are used to predict the value of a dependent variable.
The difference between the two is the number of independent variables.
As an example, let’s say that the test score of a student in an exam will be
dependent on various factors like his focus while attending the class, his
intake of food before the exam and the amount of sleep he gets before the
exam. Using this test one can estimate
the appropriate relationship among these factors.
What is logistic regression?
Logistic regression is a class of regression where the independent variable is
used to predict the dependent variable.
When the dependent variable has two categories, then it is a binary
logistic regression. When the dependent
variable has more than two categories, then it is a multinomial logistic
regression. When the dependent variable
category is to be ranked, then it is an ordinal logistic regression (OLS).
To obtain the maximum likelihood estimation, transform the dependent variable
in the logit function. Logit is
basically a natural log of the dependent variable and tells whether or not the
event will occur. Ordinal logistic
regression does not assume a linear relationship between the dependent and
independent variable. It does not assume
homoscedasticity. Wald statistics tests
the significance of the individual independent variable.
T-Test
T-test is small sample test. It was developed by William
Gosset in 1908. He published this test under the pen name of
“Student”. Therefore, it is known as Student’s t-test. For applying
t-test, the value of t-statistic is computed.
Formula is :-
t= Deviation from
the population parameter
Standard
error of the sample statistics
Example of t-test
It’s Battle of the Sexes, Round 6172. DING! We want to compare the guys and the gals on one last question before declaring a winner. So we tested 100 guys, and they scored an average of 80% with a standard deviation of 3%. The 100 gals, however, scored an average of 81% with a standard deviation of 4%. Can the gals declare victory and call it a day?
Not so fast!
Note that, although the gals have a higher score than the guys, they have a wider range of scores, too. Assuming a normal distribution, note that nearly all of the guys have scores higher than 74 (2 standard deviations below their mean — recall that, in a normal distribution, more than 95% of the scores are within two standard deviations of the mean), while some of the gals have scores below 74 (as 2 standard deviations below the gals’ mean is 73!).
Since, barring any outliers, the gals have both lower and higher scores than the guys, we are going to have to see if the gals have done better in light of both their averages and their standard deviations. To do this, we use a t-test.
Essentially, a t-test is used to compare two samples to determine if they came from the same population. Whenever we draw a sample from the population, we can reasonably expect that the sample mean will deviate from the population mean a little bit. So, if we were to take a sample of guys, and a sample of gals, we would not expect them to have exactly the same mean and standard deviation.
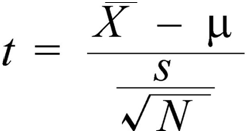
A statistically significant t-test result is one in which
a difference between two groups is unlikely to have occurred because the sample
happened to be atypical. Statistical significance is determined by the size of
the difference between the group averages, the sample size, and the standard
deviations of the groups. For practical purposes statistical significance
suggests that the two larger populations from which we sample are “actually”
different.
Chi Square Test
The Chi-Square test of Independence is used to determine
if there is a significant relationship between two nominal (categorical)
variables. The frequency of one nominal
variable is compared with different values of the second nominal variable. The data can be displayed in an R*C
contingency table, where R is the row and C is the column.
For example, a researcher wants to examine the relationship between gender
(male vs. female) and empathy (high vs. low).
The chi-square test of independence can be used to examine this
relationship. If the null hypothesis is
accepted there would be no relationship between gender and empathy. If the null hypotheses is rejected the
implication would be that there is a relationship between gender and empathy
(e.g. females tend to score higher on empathy and males tend to score lower on
empathy).
When to Use Chi-Square Test for Independence
The test procedure described in this lesson is appropriate when the following conditions are met:
The sampling method is simple random sampling.
The variables under study are each categorical.
If sample data are displayed in a contingency table, the expected frequency count for each cell of the table is at least 5.
This approach consists of four steps: (1) state the hypotheses, (2) formulate an analysis plan, (3) analyze sample data, and (4) interpret results.
State the Hypotheses
Suppose that Variable A has r levels, and Variable B has c levels. The null hypothesis states that knowing the level of Variable A does not help you predict the level of Variable B. That is, the variables are independent
H0: Variable A and Variable B are independent.
Ha: Variable A and Variable B are not independent.
The alternative hypothesis is that knowing the level of Variable A can help you predict the level of Variable B.
Note: Support for the alternative hypothesis suggests that the variables are related; but the relationship is not necessarily causal, in the sense that one variable “causes” the other.
Formulate an Analysis Plan
The analysis plan describes how to use sample data to accept or reject the null hypothesis. The plan should specify the following elements.
Significance level. Often, researchers choose significance levels equal to 0.01, 0.05, or 0.10; but any value between 0 and 1 can be used.
Test method. Use the chi-square test for independence to determine whether there is a significant relationship between two categorical variables.
Analyze Sample Data
Using sample data, find the degrees of freedom, expected frequencies, test statistic, and the P-value associated with the test statistic. The approach described in this section is illustrated in the sample problem at the end of this lesson.
Degrees of freedom. The degrees of freedom (DF) is equal to:
DF = (r – 1) * (c – 1)
where r is the number of levels for one categorical variable, and c is the number of levels for the other categorical variable.
Expected frequencies. The expected frequency counts are computed separately for each level of one categorical variable at each level of the other categorical variable. Compute r * c expected frequencies, according to the following formula.
Er,c = (nr * nc) / n
where Er,c is the expected frequency count for level r of Variable A and level c of Variable B, nr is the total number of sample observations at level r of Variable A, nc is the total number of sample observations at level c of Variable B, and n is the total sample size.
Test statistic. The test statistic is a chi-square random variable (Χ2) defined by the following equation.
Χ2 = Σ [ (Or,c – Er,c)2 / Er,c ]
where Or,c is the observed frequency count at level r of Variable A and level c of Variable B, and Er,c is the expected frequency count at level r of Variable A and level c of Variable B.
P-value. The P-value is the probability of observing a sample statistic as extreme as the test statistic. Since the test statistic is a chi-square, use the Chi-Square Distribution Calculator to assess the probability associated with the test statistic. Use the degrees of freedom computed above.
Interpret Results
If the sample findings are unlikely, given the null hypothesis, the researcher rejects the null hypothesis. Typically, this involves comparing the P-value to the significance level, and rejecting the null hypothesis when the P-value is less than the significance level.
Few links of Statistics
Tests in Statistics
A lot more to come
Keep Learning 🙂
The Data Monk