How to solve data science Hackathon
We at The Data Monk always believe in learning while coding and practicing. In this process we come across multiple things and one such learning tool is Hackathon. There are different websites like www.analyticsvidhya.com or https://www.kaggle.com/
How to solve data science Hackathon?
The best way is to get your hands dirty and start with any problem, but I have personally seen people starting with a problem and never actually reaching the solution part. So, we suggest you to follow the paths of those who have created such models.
If you are still unsure about how to make a career in Data Science, then this is your Data Science Career Path
You can also go through our Titanice Kaggle Solution
The below post is contributed by Disha Gupta

Problem statement: Create a machine learning model to predict that the person has diabetes or not.
Context: The dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective of the dataset is to diagnostically predict whether or not a patient has diabetes, based on certain diagnostic measurements included in the dataset.
Content: The dataset consists of several features like number of pregnancies, BMI, Age, Blood Pressure, Insulin level, Glucose level, Diabetes Pedigree Function and the target variable the outcome i.e. is the person suffering from diabetes (1) or not (0).
Lets first understand what every feature in the dataset mean.
- Pregnancies: It gives the number of times the female was pregnant
- Glucose: Plasma glucose concentration 2 hours in an oral glucose tolerance test
- Blood Pressure (mm Hg): Diastolic blood pressure indicates how much pressure your blood is exerting against your artery walls while the heart is resting between beats.
- Skin Thickness: Triceps skin fold thickness (mm)
- Insulin Level: 2-Hour serum insulin (mu U/ml)
- Diabetes Pedigree Function: The likelihood of a person being diabetic depending on the family history
Dataset link: https://www.kaggle.com/uciml/pima-indians-diabetes-database
Let’s start with the model building. Here, I have used RandomForest algorithm of Machine Learning using Python.
Random forest, consists of a large number of individual decision trees that operate as an ensemble . Each individual tree in the random forest spits out a class prediction and the class with the most votes becomes our model’s prediction.

We will start with importing the libraries required. So, here pandas, numpy, seaborn and matplotlib.pyplot are imported
data = pd.read_csv("./diabetes.csv")
Here, we’ll read the our data which is in csv form using pandas
data.shape
shape function helps us find number of rows and columns in the dataset. In this dataset, there are 768 rows and 9 columns
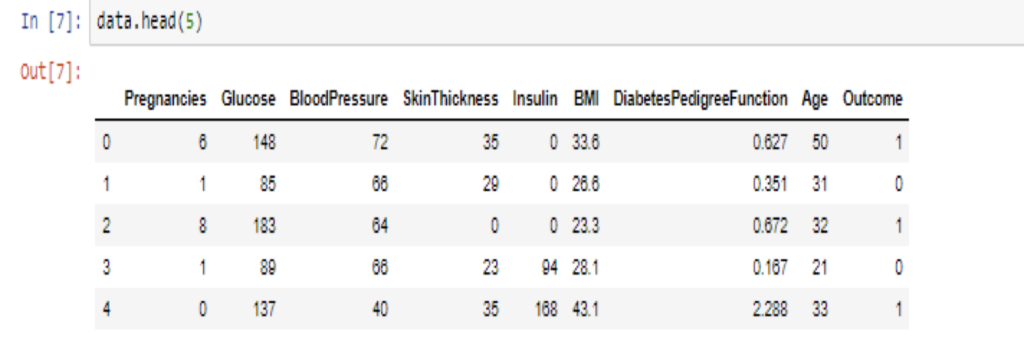
head(5) function lets us print first 5 entries in the dataset. Here, first 5 entries are printed, in which the number of people having diabetes(outcome = 1) is 3.

This line of code lets us find the number of nulls in the dataset. False as an o/p depicts that there are no nulls or Nan in the dataset
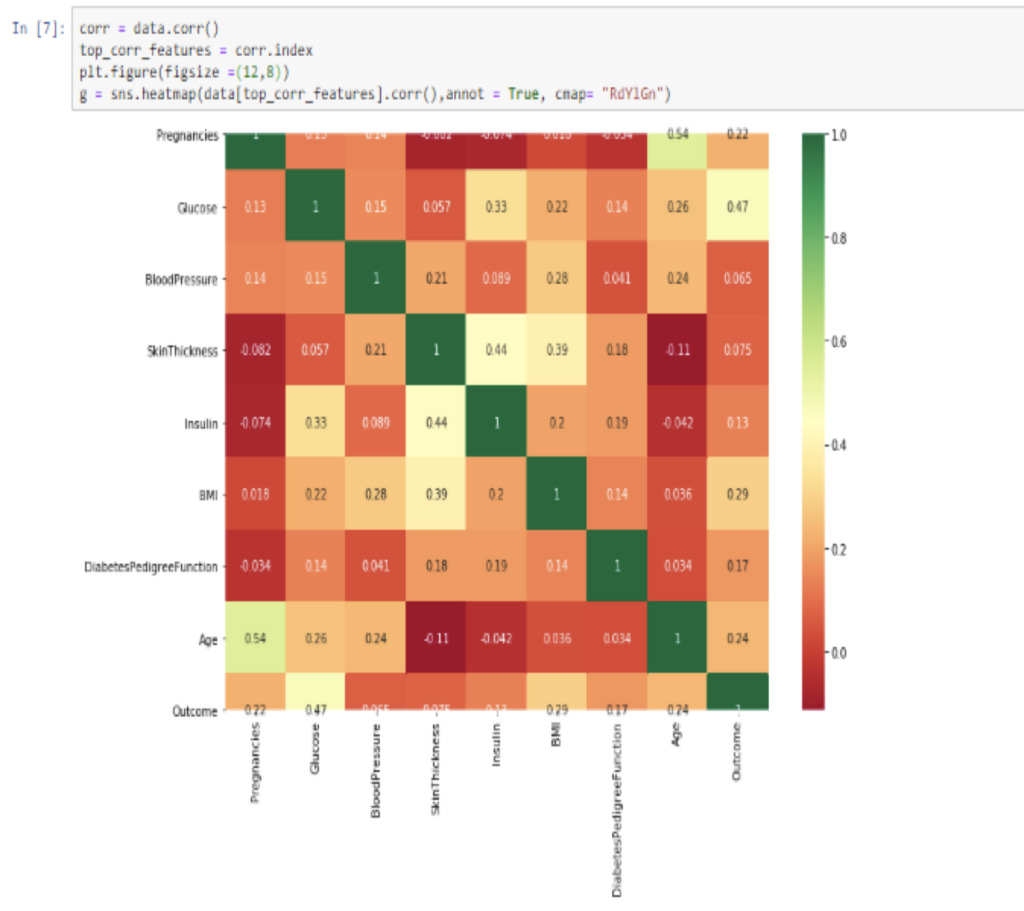
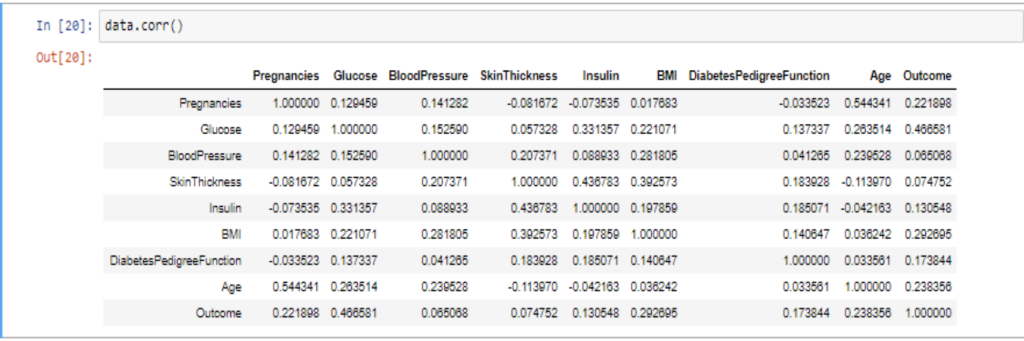
Its important to find the correlation between the features in the dataset, for finding correlation, I used corr() function, and plotting it in a heatmap gives me the result in the form of visualization. If in case, I don’t want to use any visualization, I can just use the below line of code to find the relationship between the features in the dataset.

Now I want to find the number of people/females who are diabetic and who are not diabetic, I’ll create true_count and false_count or any variable to get the count of data. So, in this dataset, 268 females are diagnosed with diabetes while 500 aren’t.
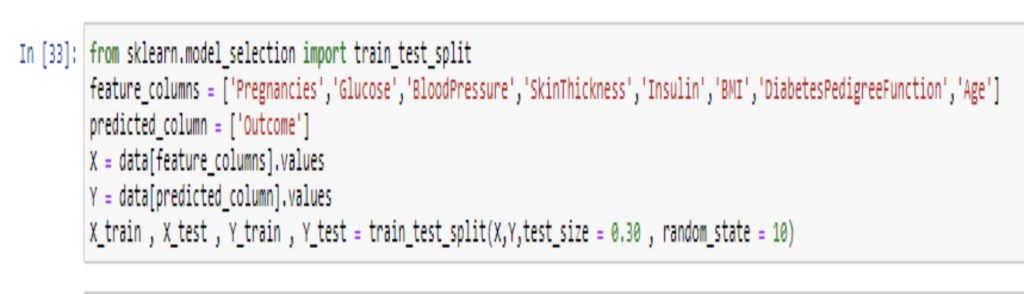
From scikit learn’s model selection, we will import train_test_split , to split the dataset into training set and test set. Here, I have separated feature columns and target column. The test size will be 30% of the entire dataset.
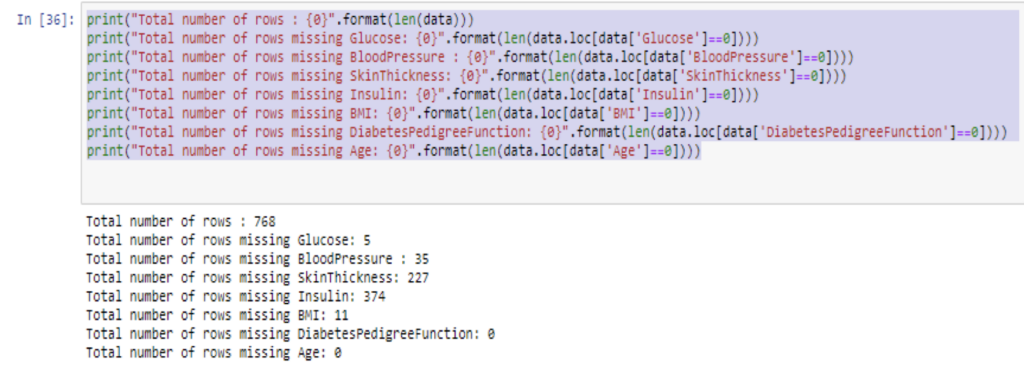
The above lines of code, is for checking all the values those are 0 in the feature columns. The below lines of code are for replacing the 0’s by the mean value using Imputer from scikit learn’s preprocessing module.

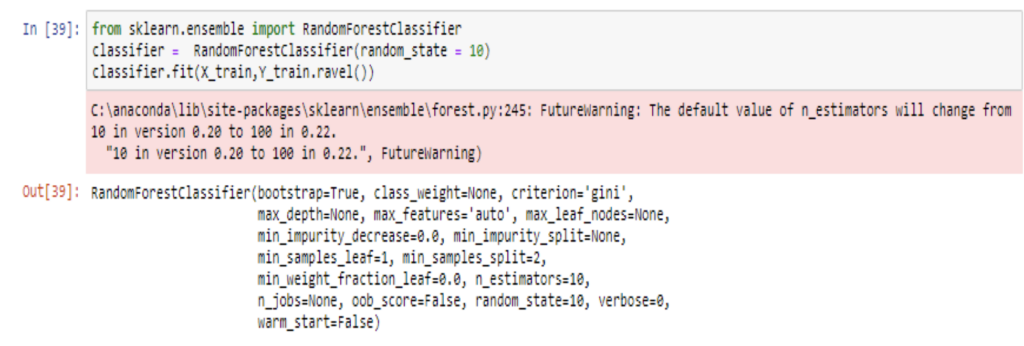
Now, lets create the ML model. I have used RandomForest algorithm which is a type of classification model. RandomForestClassifier is to be imported from ensemble module of scikit learn.
Classifier is the object created to fit the algorithm. classifier.fit will use X_train and Y_train to train the model.

After I create a model, I need to find how accurate it is in predicting the values of y or outcome. So, by using accuracy_score from metrics module of scikit learn, I’ll find the accuracy. Here the accuracy is 72.72%, which is not a bad result. But for improving accuracy, hyper parameters can used.
This was one simple approach to handle a Hackathon problem, but the secret behind high accuracy will always be feature engineering.
You can use this article as a way to understand how to start with sample data and solve Hackathons.
P.S. – There a multiple things which you can add in a problem statement to boost your accuracy but this article is not meant to solve that problem. It’s only meant to help you create your first submission to a Data Science Hackathon
The Data Monk Interview Books – Don’t Miss
Now we are also available on our website where you can directly download the PDF of the topic you are interested in. At Amazon, each book costs ~299, on our website we have put it at a 60-80% discount. There are ~4000 solved interview questions prepared for you.
10 e-book bundle with 1400 interview questions spread across SQL, Python, Statistics, Case Studies, and Machine Learning Algorithms – Ideal for 0-3 years experienced candidates
23 E-book with ~2000 interview questions spread across AWS, SQL, Python, 10+ ML algorithms, MS Excel, and Case Studies – Complete Package for someone between 0 to 8 years of experience (The above 10 e-book bundle has a completely different set of e-books)
12 E-books for 12 Machine Learning algorithms with 1000+ interview questions – For those candidates who want to include any Machine Learning Algorithm in their resume and to learn/revise the important concepts. These 12 e-books are a part of the 23 e-book package
Individual 50+ e-books on separate topics
Important Resources to crack interviews (Mostly Free)
There are a few things which might be very useful for your preparation
The Data Monk Youtube channel – Here you will get only those videos that are asked in interviews for Data Analysts, Data Scientists, Machine Learning Engineers, Business Intelligence Engineers, Analytics managers, etc.
Go through the watchlist which makes you uncomfortable:-
All the list of 200 videos
Complete Python Playlist for Data Science
Company-wise Data Science Interview Questions – Must Watch
All important Machine Learning Algorithm with code in Python
Complete Python Numpy Playlist
Complete Python Pandas Playlist
SQL Complete Playlist
Case Study and Guesstimates Complete Playlist
Complete Playlist of Statistics