1. What problems can NLP solve?
NLP can solve many problems like, automatic summarization, machine translation, named entity recognition, relationship extraction, sentiment analysis, speech recognition, and topic segmentation etc.
2. What are the common patterns used in regular expression?
\w+ -> word
\d -> digit
\s -> space
\* ->wildcard
+ or * -> greedy match
\S -> anti space i.e. it matches anything which is not a space
[A-Z] – matches all the character in the range of capital A and capital Z
3. What is the difference between match and search function?
Match tries to match the string from beginning whereas search matches it wherever it finds the pattern. The below example will help you understand better
import re
print(re.match(‘kam’, ‘kamal’))
print(re.match(‘kam’, ‘nitin kamal’))
print(re.search(‘kam’,’kamal’))
print(re.search(‘kam’,’nitin kamal’))
<re.Match object; span=(0, 3), match=’kam’>
None
<re.Match object; span=(0, 3), match=’kam’>
<re.Match object; span=(6, 9), match=’kam’>
4. How to write a regular expression to match some specific set of characters in a string?
special_char = r”[?/}{‘;]“
The above Regular Expression will take all the characters between []
5. Write a regular expression to split a paragraph every time it finds an exclamation mark
import re
exclamation = r”[!]”
strr = “Data Science comprises of innumerable topics! The aim of this 100 Days series is to get you started assuming ! that you have no prior! knowledge of any of these topics. “
excla = re.split(exclamation,strr)
print(excla)
[‘Data Science comprises of innumerable topics’, ‘ The aim of this 100 Days series is to get you started assuming ‘, ‘ that you have no prior’, ‘ knowledge of any of these topics. ‘]
6. What are the important nltk tokenizer?
sent_tokenize – Tokenize a sentence
tweet_tokenize – This one is exclusively for tweets which can come handy if you are trying to do sentiment analysis by looking at a particular hashtag or tweets
regexp_tokenize – tokenize a string or document based on a regular expression pattern
7. What is the use of .start() and .end() function?
Basically .start() and .end() helps you find the starting and ending index of a search. Below is an example:
x = re.search(“Piyush”,para)
print(x.start(),x.end())
24 30
8. Once again go through the difference between search() and match() function
Search() will find your desired regex expression anywhere in the string, but the match always looks from the beginning of the string. If a match() function hits a comma or something, then it will stop the operation then and there itself. Be very particular on selecting a function out of these
9. What is bag-of-words?
Bag-of-words is a process to identify topics in a text. It basically counts the frequency of the token in a text. Example below to help you understand the simple concept of bag-of-words
para = “The game of cricket is complicated. Cricket is more complicated than Football”
The – 1
game – 1
of-1
cricket-1
is-2
complicated-2
Cricket – 1
than – 1
Football – 1
As you can see, the word cricket is counted two times as bag-of-words is case sensitive.
10. Use the same paragraph used above and print the top 3 most common words
The code is self explanatory and is given below:
word2 = word_tokenize(para)
lower_case = [t.lower() for t in word2]
bag_of_words = Counter(lower_case)
print(bag_of_words.most_common(3))
[(‘the’, 4), (‘,’, 4), (‘data’, 3)]
11. Give an example of Lemmatization in Python
x = “running”
import nltk
nltk.download(‘wordnet’)
lem.lemmatize(x,”v”
Output
‘run’
12. What is tf-idf?
term frequency and inverse document frequency. It is to remove the most common words other than stop words which are there in a particular document, so this is document specific.

13. What is the difference between lemmatization and stemming?
Lemmatization gets to the base of the word whereas stemming just chops the tail of the word to get the base form. Below example will serve you better:
See is the lemma of saw, but if you try to get the stem of saw, then it will return ‘s’ as the stem.
See is the lemma of seeing, stemming seeing will get you see.
14. What is the flow of creating a Naïve Bayes model?
from sklearn import metrics
from sklearn.naive_bayes import MultinomialNB
# Instantiate a Multinomial Naive Bayes classifier: nb_classifier
nb_classifier = MultinomialNB()
# Fit the classifier to the training data
nb_classifier.fit(count_train,y_train)
# Create the predicted tags: pred
pred = nb_classifier.predict(count_test)
# Calculate the accuracy score: score
score = metrics.accuracy_score(y_test,pred)
print(score)
# Calculate the confusion matrix: cm
cm = metrics.confusion_matrix(y_test,pred,labels=[‘FAKE’,’REAL’])
print(cm)
15. Take the following line and break it into tokens and tag POS using function
data = “The Data Monk was started in Bangalore in 2018. Till now it has more than 30 books on Data Science on Amazon”
data = “The Data Monk was started in Bangalore in 2018. Till now it has more than 30 books on Data Science on Amazon”
#Tokenize the words and apply POS
def token_POS(token):
token = nltk.word_tokenize(token)
token = nltk.pos_tag(token)
return token
token = token_POS(data) token
Output

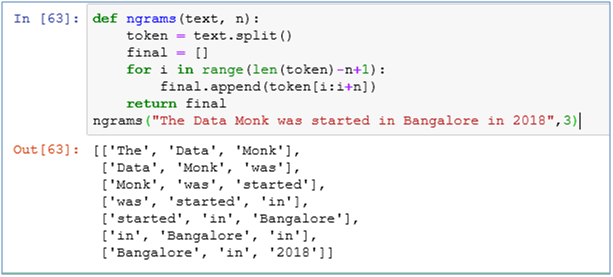
16. Create a 3-gram of the sentence below
“The Data Monk was started in Bangalore in 2018″
def ngrams(text, n):
token = text.split()
final = []
for i in range(len(token)-n+1):
final.append(token[i:i+n])
return final ngrams(“The Data Monk was started in Bangalore in 2018”,3)
Output
17. What is the right order for a text classification model components?
Text cleaning
Text annotation
Text to predictors
Gradient descent
Model tuning
18. Write a regular expression for removing special characters and numbers
review is the name of the data set and Review is the name of the column
final = []
for i in range(0,16): x = re.sub(‘[^a-zA-Z]’,’ ‘,review[‘Review’][i] )
19. Convert all the text into lower case and split the words
final = []
for i in range(0,16):
x = re.sub(‘[^a-zA-Z]’,’ ‘,review[‘Review’][i] )
x = x.lower() x = x.split()
20. What is CountVectorizer?
CountVectorizer is a class from sklearn.feature_extraction.text. It converts a selection of text documents to a matrix of token counts.
If you feel comfortable with NLP, then you can go through 80 more interview questions which are available on Amazon
100 Questions to Understand NLP using Python
Keep coding 🙂
XtraMous
The Data Monk services
We are well known for our interview books and have 70+ e-book across Amazon and The Data Monk e-shop page . Following are best-seller combo packs and services that we are providing as of now
- YouTube channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel - Website – ~2000 completed solved Interview questions in SQL, Python, ML, and Case Study
Link – The Data Monk website - E-book shop – We have 70+ e-books available on our website and 3 bundles covering 2000+ solved interview questions. Do check it out
Link – The Data E-shop Page - Instagram Page – It covers only Most asked Questions and concepts (100+ posts). We have 100+ most asked interview topics explained in simple terms
Link – The Data Monk Instagram page - Mock Interviews/Career Guidance/Mentorship/Resume Making
Book a slot on Top Mate
The Data Monk e-books
We know that each domain requires a different type of preparation, so we have divided our books in the same way:
1. 2200 Interview Questions to become Full Stack Analytics Professional – 2200 Most Asked Interview Questions
2.Data Scientist and Machine Learning Engineer -> 23 e-books covering all the ML Algorithms Interview Questions
3. 30 Days Analytics Course – Most Asked Interview Questions from 30 crucial topics
You can check out all the other e-books on our e-shop page – Do not miss it
For any information related to courses or e-books, please send an email to [email protected]