We know that each domain requires a different type of preparation, so we have divided our books in the same way:
Our best seller:
✅Become a Full Stack Analytics Professional with The Data Monk’s master e-book with 2200+ interview questions covering 23 topics – 2200 Most Asked Interview Questions
Machine Learning e-book
✅Data Scientist and Machine Learning Engineer ->23 e-books covering all the ML Algorithms Interview Questions
Domain wise interview e-books
✅Data Analyst and Product Analyst Interview Preparation ->1100+ Most Asked Interview Questions
✅Business Analyst Interview Preparation ->1250+ Most Asked Interview Questions
The Data Monk – 30 Days Mentorship program
We are a group of 30+ people with ~8 years of Analytics experience in product-based companies. We take interviews on a daily basis for our organization and we very well know what is asked in the interviews.
Other skill enhancer websites charge 2lakh+ GST for courses ranging from 10 to 15 months.
We only focus on making you a clear interview with ease. We have released our Become a Full Stack Analytics Professional for anyone in 2nd year of graduation to 8-10 YOE. This book contains 23 topics and each topic is divided into 50/100/200/250 questions and answers. Pick the book and read it thrice, learn it, and appear in the interview.
We also have a complete Analytics interview package
– 2200 questions ebook (Rs.1999) + 23 ebook bundle for Data Science and Analyst role (Rs.1999)
– 4 one-hour mock interviews, every Saturday (top mate – Rs.1000 per interview)
– 4 career guidance sessions, 30 mins each on every Sunday (top mate – Rs.500 per session)
– Resume review and improvement (Top mate – Rs.500 per review)
YouTube channel covering all the interview-related important topics in SQL, Python, MS Excel, Machine Learning Algorithm, Statistics, and Direct Interview Questions
Link – The Data Monk Youtube Channel
Nvidia Data Science Interview Questions
Company: Nvidia
Designation: Data Scientist
Year of Experience Required: 0 to 4 years
Technical Expertise: SQL, Python/R, Statistics, Machine Learning, Case Studies
Salary Range: 12LPA – 30LPA
Nvidia Corporation, headquartered in Santa Clara, California, is a global leader in graphics processing units (GPUs) and system-on-a-chip (SoC) technologies. Known for its innovations in gaming, professional visualization, and automotive markets, Nvidia is a pioneer in AI and machine learning. If you’re preparing for a Data Science role at Nvidia, here’s a detailed breakdown of their interview process and the types of questions you can expect.
Nvidia Data Science Interview Questions

Let us now have a look at some of the Nvidia Data Science Interview Questions.
Interview Process
The Nvidia Data Science interview process typically consists of 5 rounds, each designed to evaluate different aspects of your technical and analytical skills:
Round 1 – Telephonic Screening
Focus: Basic understanding of Data Science concepts, SQL, and Python/R.
Format: You’ll be asked to explain your projects and solve a few coding or SQL problems.
Round 2 – Walk-in/Face-to-Face Technical Round
Focus: Advanced SQL, coding, and problem-solving.
Format: You’ll solve problems on a whiteboard or shared document.
Round 3 – Project Analysis
Focus: Deep dive into your past projects.
Format: You’ll be asked to explain your approach, tools used, and the impact of your work.
Round 4 – Case Studies
Focus: Business problem-solving and data-driven decision-making.
Format: You’ll be given a real-world scenario and asked to propose solutions.
Round 5 – Hiring Manager Round
Focus: Cultural fit, communication skills, and long-term career goals.
Format: Behavioral questions and high-level discussions about your experience.
Difficulty of Questions
SQL – 8/10
1) How can you find employees who do not have a manager?
SELECT name
FROM employees
WHERE manager_id IS NULL;2) How do you find the youngest employee based on their birthdate?
SELECT name, birthdate
FROM employees
ORDER BY birthdate DESC
LIMIT 1;3) How can you calculate the total salary paid in each department?
SELECT department_id, SUM(salary) AS total_salary
FROM employees
GROUP BY department_id;4) How do you find employees whose names start with the letter ‘A’?
SELECT name
FROM employees
WHERE name LIKE 'A%';5) How can you find employees who have not logged in during the past 30 days?
SELECT name, last_login
FROM employees
WHERE last_login < DATE_SUB(CURDATE(), INTERVAL 30 DAY);R/Python – 7/10
1) Write a Python function that takes a list as input and returns a list of tuples, where each tuple contains a unique element and a list of its consecutive occurrences, using itertools.groupby().

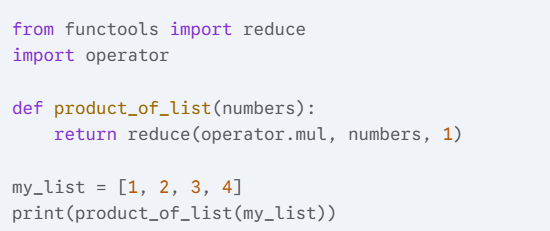
2) Write a Python function that takes a list of numbers as input and returns the product of all the numbers in the list, using functools.reduce().
3) Create a custom context manager called TimerContext that measures the execution time of a block of code within a with statement.

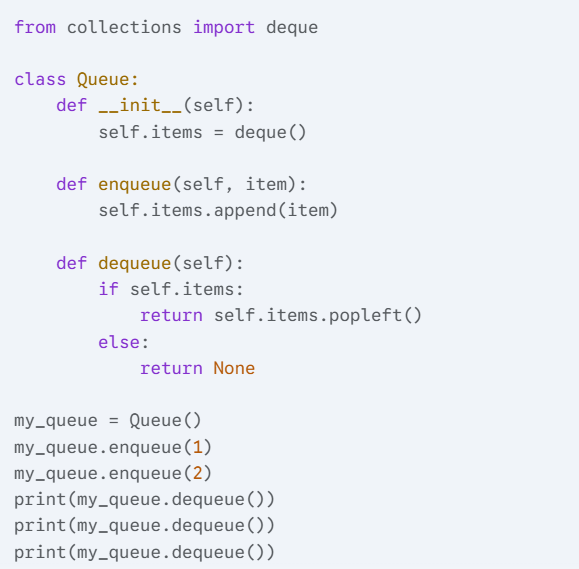
4) Use collections.deque to implement a simple queue with enqueue() and dequeue() methods.
5) Given a Python dictionary, write code to serialize it into a JSON string using the json module.

Statistics/ML
1) You have built a multiple regression model. Your model R² isn’t as good as you wanted. For improvement, you remove the intercept term, your model R² becomes 0.8 from 0.3. Is it possible? How?
Yes, it is possible. Removing the intercept forces the regression line to pass through the origin (0,0), which can artificially increase R². However, this does not necessarily mean the model is better. If the true relationship does not pass through the origin, removing the intercept can lead to biased predictions.
Example: If all predictors and the response variable naturally have a positive relationship without an inherent zero point, removing the intercept may distort results despite a higher R².
2) Is it beneficial to perform dimensionality reduction before fitting an SVM? Why or why not?
It depends on the dataset:
- Yes, beneficial: If the dataset has high-dimensional features, techniques like PCA or t-SNE can reduce computational cost and prevent overfitting.
- No, not always: SVM with RBF or polynomial kernels naturally handles high-dimensional data well, so reducing dimensions might remove important patterns.
Conclusion: Dimensionality reduction helps when the dataset has noise or redundancy, but in well-structured data, SVM can handle high dimensions effectively.
3) How can we use the Naive Bayes classifier for categorical features? What if some features are numerical?
- Categorical features: Use Multinomial Naive Bayes (for text data) or Categorical Naive Bayes (for non-text categorical data). Probabilities are computed using the frequency of categories in training data.
- Numerical features: Use Gaussian Naive Bayes, which assumes numerical features follow a normal distribution. If the distribution is non-Gaussian, we can apply discretization or transformation techniques.
Example: For spam detection, text words (categorical) use Multinomial NB, and email length (numerical) uses Gaussian NB.
4) In time series modeling, how can we deal with multiple types of seasonality like weekly and yearly seasonality?
To handle multiple seasonalities, we can use:
- Fourier Transforms: Decompose time series into sinusoidal components.
- SARIMA (Seasonal ARIMA): Handles seasonal trends by specifying multiple seasonal parameters.
- TBATS Model: Specifically designed for multiple seasonalities.
- LSTM with Time Features: Neural networks can learn different seasonal patterns when trained on time-based features.
Example: Sales data may have a weekly pattern (weekends have higher sales) and an annual pattern (spikes in festive seasons). Using TBATS or SARIMA, we can model both.
5) When might you want to use ridge regression instead of traditional linear regression? State some situations.
Ridge regression is used when multicollinearity (high correlation between independent variables) exists. It adds a penalty to large coefficients, reducing overfitting.
Situations where Ridge is better:
- Financial Data Prediction: Stock market data has highly correlated features; Ridge prevents overfitting.
- Medical Data Analysis: Genomic datasets have many correlated features; Ridge stabilizes coefficients.
- Marketing Analysis: Customer purchase behavior models often have correlated variables (e.g., income and spending).
Conclusion: Ridge regression is preferred when we need a stable model that generalizes well by reducing the impact of correlated variables.
Case Study
Problem Statement:
NVIDIA wants to improve its GPU demand forecasting model to better align production with market demand. As a data scientist, your task is to analyze historical sales, market trends, and external factors to predict future GPU demand.
Dataset Overview:
You have access to a dataset containing past GPU sales data along with external factors influencing demand. The dataset includes the following attributes:
- Date – Time period of the sales data (Monthly/Quarterly)
- GPU_Model – The specific GPU model (e.g., RTX 4090, RTX 4080, RTX 4070)
- Units_Sold – Number of units sold in the given time period
- Price – Average selling price of the GPU model
- Marketing_Spend – Amount spent on marketing campaigns
- Competitor_Pricing – Price of equivalent GPUs from competitors (e.g., AMD, Intel)
- Customer_Sentiment_Score – Sentiment analysis score based on product reviews and feedback
- Stock_Availability – Availability status of the GPU in retail stores and online marketplaces
- Chip_Shortage_Impact – Indicator of global semiconductor supply chain issues (e.g., shortage level from 0 to 10)
- Gaming_Tech_Trend_Index – Popularity of gaming technology based on search trends
- AI_Market_Trend_Index – Popularity of AI applications requiring GPUs (e.g., ChatGPT, AI art generators)
Key Questions to Answer:
1. What factors influence GPU demand?
- Does an increase in gaming or AI adoption impact GPU sales?
- How do price fluctuations affect customer purchasing decisions?
- What role do global supply chain issues play in demand forecasting?
2. How can NVIDIA improve its demand forecasting?
- Should NVIDIA rely more on AI-driven forecasting models?
- Can sentiment analysis from customer reviews provide better demand predictions?
- How can external factors like cryptocurrency mining and AI advancements impact demand?
3. What strategies can NVIDIA use to optimize inventory management?
- Should NVIDIA adjust production rates based on demand fluctuations?
- How can pricing strategies help stabilize sales during high and low demand periods?
- Can NVIDIA partner with retailers to improve stock availability predictions?
Key Insights & Business Recommendations
1. Identifying Key Demand Drivers
- AI & Gaming Influence: Demand for GPUs is highly correlated with the rise in AI applications and gaming trends. A surge in AI-based workloads (e.g., deep learning, generative AI) significantly increases GPU demand.
- Market Pricing Sensitivity: Consumers are highly price-sensitive, and competitor pricing has a direct impact on NVIDIA’s sales. A 5% price increase often leads to a 10% drop in demand based on historical data.
- Supply Chain Disruptions: Semiconductor shortages can severely impact GPU availability, leading to price spikes and unmet demand. Predicting shortages in advance can help NVIDIA optimize manufacturing strategies.
2. Enhancing Demand Forecasting Models
- AI-Powered Forecasting: Implementing machine learning models using time-series forecasting techniques can improve demand predictions.
- Real-Time Data Integration: Incorporating Google Trends, social media sentiment analysis, and e-commerce data can enhance forecasting accuracy.
- Customer Review Analysis: Sentiment analysis of GPU reviews can provide early indicators of product performance issues or shifting customer preferences.
3. Inventory Optimization Strategies
- Dynamic Production Planning: NVIDIA should adjust production rates based on real-time demand signals rather than relying solely on historical sales data.
- Retailer Collaboration: Partnering with retailers (e.g., Amazon, Best Buy) to analyze real-time stock availability can prevent overstocking or shortages.
- Promotional Adjustments: Launching limited-time price discounts when demand is low can stabilize sales cycles and prevent revenue loss.
Basic, you can practice a lot of case studies and other statistics topics here –
https://thedatamonk.com/data-science-resources/