

Statistics Interview Questions
1
2. What is a sample?
A sample is like a subset of the population. Most of the times you won’t be able to do your complete analysis on the Population data set as there will be hundreds of millions of rows and processing it will consume a lot of time. So, we take a sample of data which should be random and unbiased from the population.
3. What is a nominal data set?
Nominal data is recorded as categories in a data set. For example, rocks can be generally categorized as igneous, sedimentary and metamorphic.
4. What are the types of variables?
Discrete Variable – A variable with a limited number of values (e.g., gender (male/female), college class (freshman/sophomore/junior/senior)
Continuous Variable – A variable that can take on many different values, in theory, any value between the lowest and highest points on the measurement scale.
Independent Variable – A variable that is manipulated, measured, or selected by the researcher as an antecedent condition to
Dependent Variable – A variable that is not under the experimenter’s control — the data. It is the variable that is observed and measured in response to the independent variable.
Qualitative Variable – A variable based on categorical data.
Quantitative Variable – A variable based on quantitative data.
In general, statistics is a study of data: describing properties of the data, which is called descriptive statistics and drawing conclusions about a population of interest from information extracted from a sample, which is called inferential statistics.
5.
1. Measures of Center –Mean, Median and Mode
2.
3. Measures of Shape –Symmetric, Skewness, Kurtosis
6. Define mean.
The mean is the most common measure of central tendency and the one that can be mathematically manipulated. It is defined as the average of
Example:
Heights of five people: 5 feet 6 inches, 5 feet 7 inches, 5 feet 10 inches, 5 feet 8 inches, 5 feet 8 inches.
The sum
Divide 339 by 5 people = 67.8 inches or 5 feet 7.8 inches.
The mean (average) is 5 feet 7.8 inches.
7. Give an example of a median.
Find the median of 5 feet 6 inches, 5 feet 7 inches, 5 feet 10 inches, 5 feet 8 inches, 5 feet 8 inches.
Line up your numbers from smallest to largest: 5 feet 6 inches, 5 feet 7 inches, 5 feet 8 inches, 5 feet 8 inches, 5 feet 10 inches.
The median
Even amount of numbers: Find the median of 7, 2, 43, 16, 11, 5
Line up your numbers in order: 2, 5, 7, 11, 16, 43
Add the 2 middle numbers and divide by 2: 7 + 11 = 18 ÷ 2 = 9
The median is 9.
8. Give an example of mode.
Example: Height Chart with people lined up in order of height, short to tall.
Find the mode of 5 feet 6 inches, 5 feet 7 inches, 5 feet 10 inches, 5 feet 8 inches, 5 feet 8 inches.
Put the numbers
The mode is 5 feet 8 inches (it occurs the most, at 2 times).
9. What is IQR?
The interquartile range is a measure of where the “middle fifty” is in a data set. Where a range is a measure of where the beginning and end are in a set, an interquartile range is a measure of where the bulk of the values lie. That’s why it’s preferred over many other measures of spread (i.e. the average or median) when reporting things like school performance or SAT scores.
10. How to calculate IQR?
Step 1: Put the numbers in order.
1, 2, 5, 6, 7, 9, 12, 15, 18, 19, 27.
Step 2: Find the median.
1, 2, 5, 6, 7, 9, 12, 15, 18, 19, 27.
Step 3: Place parentheses around the numbers above and
below the median.
Not necessary statistically, but it makes Q1 and Q3 easier to spot.
(1, 2, 5, 6, 7), 9, (12, 15, 18, 19, 27).
Step 4: Find Q1 and Q3
Think of Q1 as a median in the lower half of the data and think of Q3 as a
median for the upper half of data.
(1, 2, 5, 6, 7), 9, ( 12, 15, 18, 19,
27). Q1 = 5 and Q3 = 18.
Step 5: Subtract Q1 from Q3 to find the interquartile
range.
18 – 5 = 13.
11. Define the measure of shape.
Measure of Shape
For
distributions summarizing data from continuous measurement scales, shape of
graph can be used to describe how the distribution rises and drops.
Symmetric – Distributions that have the same shape on both sides of
the center are called symmetric. A
symmetric distribution with only one peak is referred to as a normal
distribution.
Skewness – Skewness is a measure of the asymmetry
of the probability distribution of a real-valued random variable about its
mean. The skewness value can be positive or negative, or even undefined. The
qualitative interpretation of the skew is complicated and unintuitive.
12. What
Positively skewed – A distribution is positively skewed when

Negatively skewed – A negatively skwed distribution has an extended tail pointing to the left (smaller numbers) and reflects bunching of numbers in the upper part of the distribution with fewer scores at the lower end of the measurement scale.

The formula to find skewness manually is this:
skewness = (3 * (mean – median)) / standard deviation
13. What is the correlation?
Correlation is one of the most basic and important concepts in data science. In a layman language, it is used to get the degree of relationship between 2 variables.
For example – Height and Weight are related i.e. taller people are generally heavier than the shorter one. But, the correlation between these might not be perfect.
Consider the variables family income and family expenditure. It is well known that income and expenditure increase or decrease together. Thus they are related in the sense that change in any one variable is accompanied by the change in the other variable.
Correlation can tell you something about the relationship between variables. It is used to understand:
1. Whether the relationship is positive or negative
2. The strength of the relationship.
Correlation is a powerful tool that provides these vital pieces of information.
In the case of family income and family expenditure, it is easy to see that they both rise or fall together in the same direction. This is called a positive correlation.
14. What are the two types of regression?
There are two types of regression analysis:-
1. Linear Regression Analysis
2. Multiple Regression Analysis
15. What is Linear Regression?
Starting with Linear Regression Analysis, It is basically a technique used to determine/predict the unknown value of a variable by looking at the known values. If X and Y are two variables which are related, then linear regression helps you to predict the value of Y.
A simple example can be the relationship between age of a person and his maturity level. So we can say that these 2 are related and we can guess the maturity level of the person.
By linear regression, we mean models with just one independent and one dependent variable. The variable whose value is to be predicted is known as the dependent variable and the one whose known value is used for prediction is known as the independent variable.
Y = a + bX
This is the linear regression of Y on X where a and b are unknown constant and slope of the equation.
Choice of linear regression is one of the most important parts of applying it. For example, suppose you want to have 2 variables, crop yield (Y) and rainfall (X). Here the construction of the regression line of Y on X would make sense and would be able to demonstrate the dependence of crop yield on rainfall. We would then be able to estimate crop yield given rainfall.
Careless use of linear regression analysis could mean construction of regression line of X on Y which would demonstrate the laughable scenario that rainfall is dependent on crop yield; this would suggest that if you grow really big crops you will be guaranteed a heavy rainfall.
If the regression coefficient of Y on X is 0.53 units, it would indicate that Y will increase by 0.53 if X increased by 1 unit. A similar interpretation can be given for the regression coefficient of X on Y.
16. What is multiple linear regression?
As the name suggests, multiple linear regression uses 2 or more variables as a predictor to get the value of the unknown variable.
For example, the yield of rice per acre depends upon the quality of seed, the fertility of soil, fertilizer used, temperature, rainfall. If one is interested to study the joint effect of all these variables on rice yield, one can use this technique.
An additional advantage of this technique is it also enables us to study the individual influence of these variables on yield.
Y = b0 + b1 X1 + b2 X2 + …………………… + bk Xk
Here b0 is the intercept and b1,b2,b3, etc. are analogous to the slope in the linear regression.
You need to know whether your regression is good or not. In order to judge your regression model examine the coefficient of determination(R2) which always lies between 0 and 1. The closer the value of R2 to 1, the better is the model.
A related question is whether the independent variables individually influence the dependent variable significantly. Statistically, it is equivalent to testing the null hypothesis that the relevant regression coefficient is zero.
This can be done using t-test. If the t-test of a regression coefficient is significant, it indicates that the variable is in question influences Y significantly while controlling for other independent explanatory variables.
17. What are the major differencws between Linear and Multi linear regression?
In simple linear regression a single independent variable is used to predict the value of a dependent variable. In multiple linear regression two or more independent variables are used to predict the value of a dependent variable. The difference between the two is the number of independent variables.
As an example, let’s say that the test score of a student in an exam will be dependent on various factors like his focus while attending the class, his intake of food before the exam and the amount of sleep he gets before the exam. Using this test one can estimate the appropriate relationship among these factors.
18. What is Logistic Regression?
Logistic regression is a class of regression where the independent variable is used to predict the dependent variable. When the dependent variable has two categories, then it is a binary logistic regression. When the dependent variable has more than two categories, then it is a multinomial logistic regression. When the dependent variable category is to be ranked, then it is an ordinal logistic regression (OLS).
To obtain the maximum likelihood estimation, transform the dependent variable in the logit function. Logit is basically a natural log of the dependent variable and tells whether or not the event will occur. Ordinal logistic regression does not assume a linear relationship between the dependent and independent variable. It does not assume homoscedasticity. Wald statistics tests the significance of the individual independent variable.
19. Can Standard Deviation be False?
The formula for standard deviation is given below
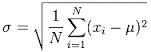
Since the differences are squared, added and then rooted, negative standard deviations are not possible.
20. What is p-value and give an example?
In statistical significance testing, the p-value is the probability of obtaining a test statistic at least as extreme as the one that was actually observed, assuming that the null hypothesis is true. If the p-value is less than 0.05 or 0.01, corresponding respectively to a 5% or 1% chance of rejecting the null hypothesis when it is true (Type I error).
Example: Suppose that the experimental results show the coin turning up heads 14 times out of 20 total flips
* null hypothesis (H0): fair coin;
* observation O: 14 heads out of 20 flips; and
* p-value of observation O given H0 = Prob(≥ 14 heads or ≥ 14 tails) = 0.115.
The calculated p-value exceeds 0.05, so the observation is consistent with the null hypothesis — that the observed result of 14 heads out of 20 flips can be ascribed to chance alone — as it falls within the range of what would happen 95% of the time were this in fact the case. In our example, we fail to reject the null hypothesis at the 5% level. Although the coin did not fall evenly, the deviation from expected outcome is small enough to be reported as being “not statistically significant at the 5% level”.
<sites.google.com>
Questions from Statistics are mostly around the following topics:-
1. Regression
2. Tests in Statistics
3. Hypothesis testing
4. Mean, Median, and Mode
5. Correlation, Standard Deviation, and Variance
This page will be updated every few days. Keep checking the page.
XtraMous
Comments ( 2 )
Hey! Do you use Twitter? I’d like to follow you if that would be ok. I’m absolutely enjoying your blog and look forward to new updates.
This is one awesome blog article.Much thanks again.